
本站原创文章,转载请说明来自《老饼讲解-机器学习》www.bbbdata.com
bins.Bins - 分箱类函数(单变量)
bins.Bins是单个变量的分箱类对象,它用单个变量的分箱配置进行初始化
bins.Bins类完整的初始化格式如下:
b = bins.Bins(bin_set,with_null=False,with_other=False)1. 入参说明
数据类型:list
数据类型:bool
数据类型:bool
简单来说,就是如果with_null=True,即使bin_set中没有配置空值,也会将空值作为一个独立分箱
类似地,with_other=True,就是即使bin_set中没有配置'_others',也会"其它"作为一个独立分箱
2.1. 类的属性
在初始化完bins.Bins类后,它有如下的属性:
数据类型:list
数据类型:dict
数据类型:pandas.DataFrame
数据类型:dict
2.1. 类的方法
在初始化完bins.Bins类后,它有如下的方法:
binStat:分布统计函数
binStat用于统计样本数据在分箱上的分布,完整调用格式如下:
bin_stat = b.binStat(x,y) # 这里的b指的是一个bins.Bins类binStat-入参说明:
数据类型:单列pandas.core.series
数据类型:单列pandas.core.series
binStat-出参说明:
binStat共7列,它是形式如下的DataFrame:
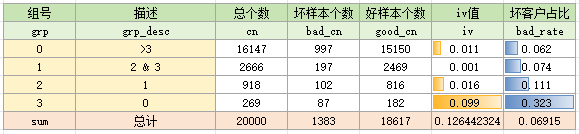
即样本在每个分箱上的组号、描述、总个数、坏样本个数、好样本个数、IV和badRate,以及总计信息
bins.Bins类使用示例如下:
import bbbrisk as br
# 加载数据
data = br.datasets.load_bloan_grp() # 加载数据
x,y = data['rev'],data['is_bad'] # 变量与标签
# 初始化分箱类
bin_set = [['-',0.1],[0.1,1.2],[1.2,2],[2,'+']]
b = br.bins.Bins(bin_set,with_null=False,with_other=False) # 将分箱初始化为分箱Bins类
# 打印分箱类的属性
print('\n* bin_set(分箱配置):\n',b.bin_set ) # 显示转换后的分组数据
print('\n* bin_range(分箱范围):\n',b.bin_range ) # 显示转换后的分组数据
print('\n* bin_desc(分箱描述):\n',b.bin_desc ) # 显示转换后的分组数据
print('\n* bin_desc_dict(分箱描述字典):\n',b.bin_desc_dict ) # 显示转换后的分组数据
# 统计样本在分箱上的分布
bin_stat = b.binStat(x,y) # 用Bins类来统计x,y在分箱上的分布
br.display.pd.set(width=300,max_colwidth=30,max_rows=30) # 美化pandas的显示方式
print('\n* 样本在分箱的分布:\n',bin_stat) # 显示样本分布运行结果如下:
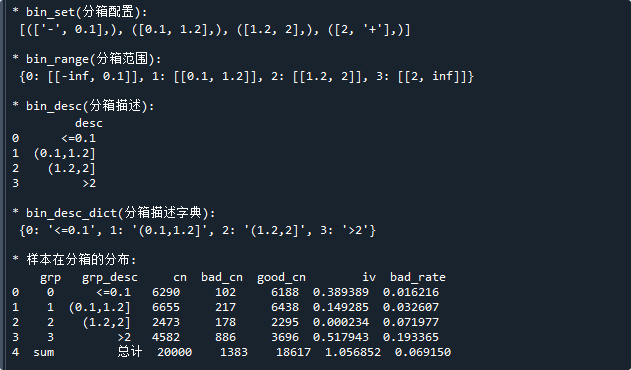
从上述代码与结果可以看到,bin.Bins类主要用于将分箱配置转换为分箱类
转换为分箱类后,就可以看到它每个分箱的范围、描述等信息
并可以使用binStat方法来统计出样本在该分箱上的分布情况,以及iv、badRate等
特别地,代码中加入了br.display.pd.set来美化DataFrame的显示效果,这是因为分箱统计内容往往过多,直接打印显示不美观
import bbbrisk as br
# 加载数据
data = br.datasets.load_bloan_grp() # 加载数据
x,y = data['rev'],data['is_bad'] # 变量与标签
# 未配置None时,with_null=True的效果
bin_set = [['-',0.1],[0.1,1.2],[1.2,2],[2,'+']] # 分箱配置,不处理了None
b = br.bins.Bins(bin_set,with_null=True,with_other=False) # 将分箱初始化为分箱Bins类
bin_stat = b.binStat(x,y) # 统计样本在分箱上的分布
print('\n* 未配置None时:\n',bin_stat) # 显示样本分布
# 已配置None时,with_null=True的效果
bin_set = [(['-',0.1],None),[0.1,1.2],[1.2,2],[2,'+']] # 分箱配置,处理了None
b = br.bins.Bins(bin_set,with_null=True,with_other=False) # 将分箱初始化为分箱Bins类
bin_stat = b.binStat(x,y) # 统计样本在分箱上的分布
print('\n* 已配置None时:\n',bin_stat) # 显示样本分布运行结果如下:
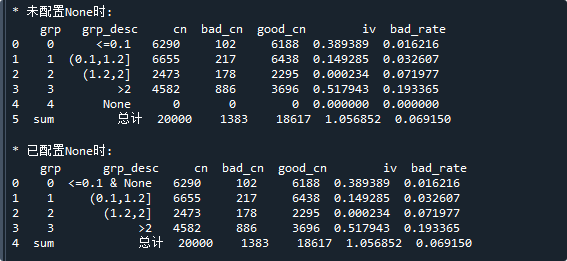
只要设置with_null=True,不管分箱配置有没有处理空值,最终都会处理空值
从结果中可以看到,当分箱配置没有None时,会添加一个None分箱
当分箱配置已经有None时(本例中将None设置在第一个分箱),则不作处理
import bbbrisk as br
# 加载数据
data = br.datasets.load_bloan_grp() # 加载数据
x,y = data['rev'],data['is_bad'] # 变量与标签
# 未配置other时,with_other=True的效果
bin_set = [['-',0.1],[0.1,1.2],[1.2,2],[2,'+']] # 分箱配置,不处理other
b = br.bins.Bins(bin_set,with_null=False,with_other=True) # 将分箱初始化为分箱Bins类
bin_stat = b.binStat(x,y) # 统计样本在分箱上的分布
print('\n* 未配置other时:\n',bin_stat) # 显示样本分布
# 已配置other时,with_other=True的效果
bin_set = [(['-',0.1],'_other'),[0.1,1.2],[1.2,2],[2,'+']] # 分箱配置,处理了other
b = br.bins.Bins(bin_set,with_null=False,with_other=True) # 将分箱初始化为分箱Bins类
bin_stat = b.binStat(x,y) # 统计样本在分箱上的分布
print('\n* 已配置other时:\n',bin_stat) # 显示样本分布运行结果如下:
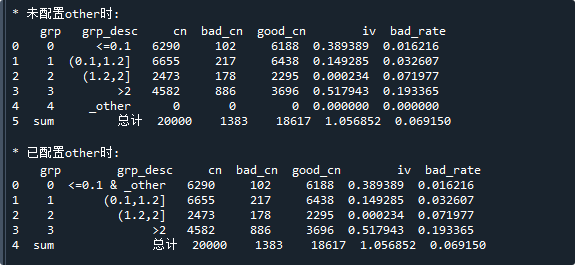
with_other与with_null是类似的
只要设置with_other=True,不管分箱配置有没有处理"其它值",最终都会处理"其它值"
从结果中可以看到,当分箱配置没有'_other'时,会添加一个'_other'分箱
当分箱配置已经有'_other'时(本例中将'_other'设置在第一个分箱),则不作处理
好了,以上就是bins.Bins类函数的使用方法了~
End