本站原创文章,转载请说明来自《老饼讲解-机器学习》www.bbbdata.com
k-means(K均值算法)是聚类算法中的入门基本算法,它以简单、计算量低、有效而知名
本文讲解K-means的算法流程、相关距离公式、优缺点,以及展示一个K-means的使用例子
通过本文可以快速了解K-means算法是什么,使用K-means时需要注意什么,以及如何使用它对样本进行聚类
本节介绍K-means聚类算法的流程,快速了解K-means聚类是什么
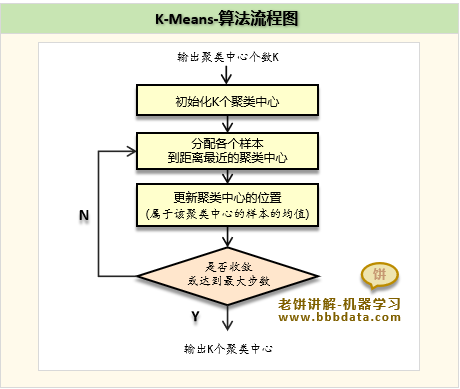
k-means聚类算法流程
k-means聚类又称为K均值聚类,它属于无监督学习,用于将无标签的样本聚为K类
由于k-means聚类流程简单,计算量低,因此它是最为常用的聚类算法之一
k-means聚类算法流程
k-means聚类算法流程如下:
1. 初始化K个聚类中心
2. 将每个样本划分到离它最近的聚类中心
这里需要先计算各个样本与聚类中心的距离,再进行划分
3. 将每个聚类中心更新为样本质心
将所有属于第i个聚类中心的样本的均值,作为第k个聚类中心的位置
4. 重复2、3,直到达到终止条件
终止条件为:达到最大迭代次数或聚类中心变化很小
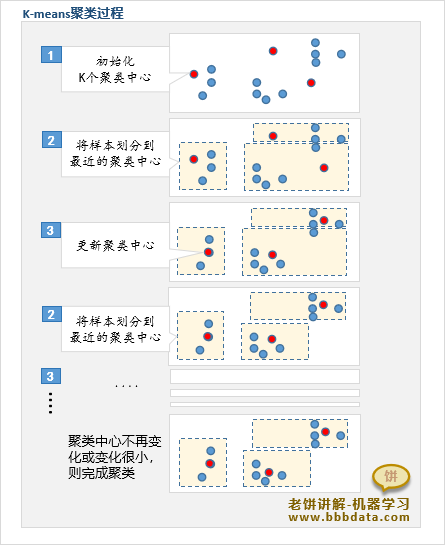
k-means聚类过程示例
k-means聚类过程示例如下:
本节介绍K-means的关键设置:中心初始化、K值选择和距离公式
K-means的关键参数
在实际使用中,k-means算法的关键设置如下:
👉 中心的初始化
👉 K值的选择
👉 距离公式
一、K值的选择
根据数据背景意义来推断样本大概有多少个类别,从而确定聚类中心个数K
在不太明确的时候,可以设置5类左右,对数据进行预试探
为什么设5类呢?因为如果真实类别小于5类,那后期合并即可
如果多于5类,那至少也能先聚出几个类别,后面再增加即可
二、聚类中心的初始化
常用的方法是随机选取k个样本作为聚类中心
三、距离公式
最常用的距离公式就是欧氏距离,余弦距离, 曼哈顿距离
欧氏距离的计算公式如下:
余弦距离的计算公式如下:
曼哈顿距离计算公式如下:
还有一大堆距离,例如切比雪夫距离 、闵可夫斯基距离、马氏距离等等,
日常中基本用欧氏距离,一般欧氏距离效果不好再考虑其它距离
K-means的一些使用经验
下面是K-means使用时的相关经验
1. K-means对初始化比较敏感,需多次尝试
kmeans非常受初始化的影响,因此,一般采用随机初始化
然后多次聚类并用SSE进行评估,哪个结果好,就用哪个
2. 类别个数需要多次尝试
kmeans 对 K值也是敏感的,也需要多次尝试
✍️聚类结果评估函数-误差平方和 (SSE)
SSE的计算公式如下:
: 所属的聚类中心
即所有样本到其所属聚类中心的距离平方之和
本节展示如何使用代码来实现K-means聚类
K-means代码实例
下面展示如何使用sklearn来实现一个k-means聚类
具体代码如下
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn import cluster
# -----------生成数据-----------------
X, y = make_blobs(n_samples=150, random_state=10,centers=5) #生成数据
# ---------模型训练与预测-------------
clf = cluster.KMeans(n_clusters=5, max_iter=300,random_state=0) # 初始化k-means聚类模型
clf.fit(X) # 进行聚类
y = clf.predict(X) # 输出每个样本的类别
# --------------打印结果---------------
print('\n聚类中心:\n',clf.cluster_centers_) # 打印聚类中心
#展示结果,以颜色标示类别
fig, axes = plt.subplots(2, 1,figsize=(8, 6)) # 初始化画布
plt.subplots_adjust(wspace=0.2, hspace=0.3) # 调整子图之间的间隔
plt.rcParams["font.sans-serif"] = ["SimHei"] # 设置中文
plt.rcParams['axes.unicode_minus'] = False # 设置坐标轴负号显示方式
axes[0].set_title('原始样本') # 设置第一个子图的标题
axes[0].scatter(X[:, 0], X[:, 1]) # 画出聚类前的样本分布
axes[1].set_title('k-means 聚类结果') # 设置第一个子图的标题
axes[1].scatter(X[:, 0], X[:, 1], c=y) # 画出聚类后的各个样本的类别运行结果如下:
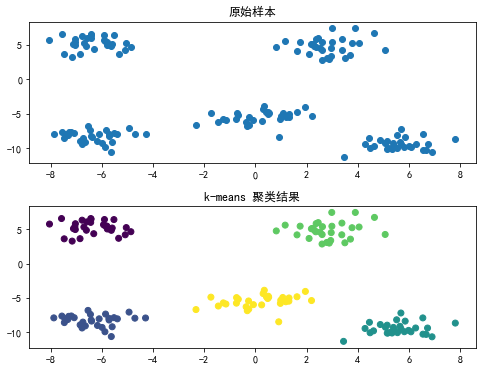
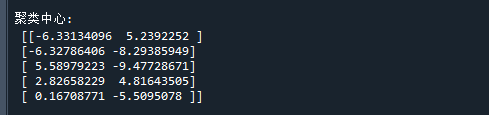
可以看到,K-means聚类能很好地把每一簇样本聚为一类
K-means的优缺点
优点
K-means的优点是计算量低,相比其它聚类算法,不会因为样本量而暴增
k-means每次只需计算样本与类别的距离,而不是样本与样本间的距离
而类别个数是很小的,所以 k-means相对于其它聚类算法计算量不大
缺点
1. K值需要先验经验去决定
k值需要用先验经验决定,而往往这恰好是缺失的
如果k值设置得不好,会严重影响聚类结果
2. 对异常点较敏感
k-means对异常点较为敏感,异常点极大时会严重影响聚类中心的位置
3. 对球状的数据比较好用
对球状的数据比较好用,但在数据为非球状数据时,效果可能会不佳
K-means最最最大的优点就是计算较为简单
聚类的方法千千万种,但K-means经典不衰就是因为它的计算量在众多聚类算法中是最简单的
以上就是K-means聚类算法的全部内容了
End