
本站原创文章,转载请说明来自《老饼讲解-机器学习》www.bbbdata.com
model.scoreCard - 评分卡模型构建函数
model.scoreCard用于构建一个评分卡模型
完整调用格式如下:
logit_model,card = model.scoreCard(x,y,bin_sets,train_param={})1. 入参说明
数据类型:pandas.DataFrame
数据类型:pandas.core.series
bin_set也可以传入字符串'grp',此时代表X数据是已经是分组数据(即组号) ,不需分箱
train_param的可设参数有:
test_size:模型训练时预留的测试数据比例,默认值为20%
penalty :逻辑回归模型的正则化方式,None代表不用正则化、'l2'代表用L2正则化,默认值为'l2'
它与sklearn的逻辑回归参数模型一致,更多参考sklearn逻辑回归模型的penalty参数
select_var:是否在训练前使用逐步回归选择变量,True或False,默认为True
select_tol:使用逐步回归选择变量时,当AUC提升小于select_tol时,则停止添加变量,默认值为0.005
random_state:随机种子,逻辑回归模型的训练以及选择测试数据集时的随机种子,默认值为None
备注:train_param可设置部分参数,例如train_param={'random_state':0}代表只将随机种子设为0,其它训练参数用默认值
2. 出参说明
数据类型:bbbrisk的_LogitModel类
数据类型:bbbrisk的_Card类
总的来说,model.scoreCard就是通过传入x,y数据,并指定X的分箱(同时可以选择性设置模型训练的参数),
然后model.scoreCard函数就会构建出评分卡的结果,包括评分卡中所使用的逻辑回归模型,以及最终的评分卡表
可以通过返回的logit_model和card进行应用,例如预测样本、查看评分卡表等等,详细参考_LogitModel类和bbbrisk的_Card类的说明
model.scoreCard使用示例如下
示例一:使用x,y与分箱配置进行构建评分卡
import bbbrisk as br
data = br.datasets.load_bloan() # 加载数据
x,y = data.iloc[:,:-1],data['is_bad'] # 样本变量与标签
bin_sets = br.bins.batch.autoBins(x, y,enum_var=['city','marital']) # 自动分箱,如果有枚举变量,必须指出哪些是枚举变量
model,card = br.model.scoreCard(x,y,bin_sets,train_param={'random_state':0}) # 构建评分卡,为了使结果能重现,笔者设置了固定的随机种子
score = card.predict(x[card.var]) # 用评分卡进行评分
br.display.pd.set(width=300,max_colwidth=30,max_rows=30) # 美化pandas的显示方式
print('\n* 评分卡的特征分:\n',card.featureScore ) # 评分卡-特征得分表
print('\n* 评分卡的基础分:',card.baseScore) # 评分卡-基础分运行结果如下:
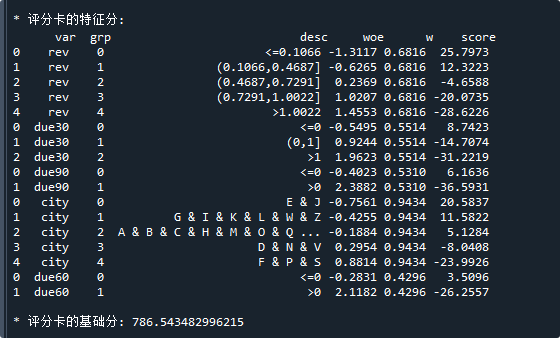
示例二:使用x的分组数据与标签y构建评分卡
import bbbrisk as br
data = br.datasets.load_bloan_grp() # 加载分组数据
x,y = data.iloc[:,:-1],data['is_bad'] # 样本变量与标签
model,card = br.model.scoreCard(x,y,'grp',train_param={'random_state':0}) # 构建评分卡,为了使结果能重现,笔者设置了固定的随机种子
score = card.predict(x[card.var]) # 用评分卡进行评分
br.display.pd.set(width=300,max_colwidth=30,max_rows=30) # 美化pandas的显示方式
print('\n* 评分卡的特征分:\n',card.featureScore ) # 评分卡-特征得分表
print('\n* 评分卡的基础分:',card.baseScore) # 评分卡-基础分运行结果如下:
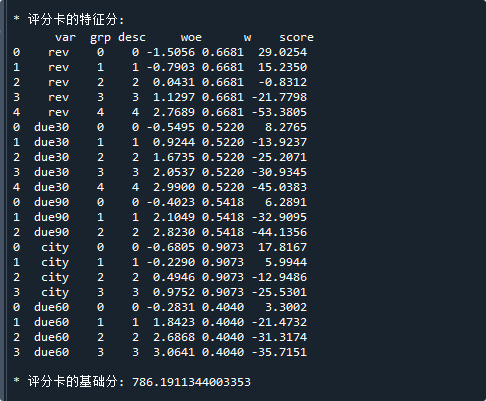
好了,以上就是model.scoreCard函数的使用方法了~
End