
本站原创文章,转载请说明来自《老饼讲解-机器学习》www.bbbdata.com
在用sklearn训练完决策树后,往往我们需要将决策树中的数据提取出来使用,
本文讲解如何提取训练好的决策树数据,并用demo说明每个数据的意义
本节讲解sklearn构建好决策树之后,如何查看决策树的规则和节点上的内容
问题描述
用sklearn建好决策树后,可以打印出树的结构:
但往往我们提取图中的数据(例如用于将决策树转化成规则代码)
那图中的数据究竟在哪呢?
下面我们讲解如何在sklearn训练好决策树后,如何提取决策树中的规则与节点数据
决策树信息存储位置
决策树模型主要有如下两类信息:
👉1. 树结构信息
树结构信息以左右节点编号的形式来表示
👉2.节点信息
树节点信息包括分割变量、分割修士、不纯度等等
树模型的信息存储在决策树模型对象clf的属性中,具体如下:
决策树结构信息
左节点编号 : clf.tree_.children_left
右节点编号 : clf.tree_.children_right
节点信息
分割的变量 : clf.tree_.feature
分割的阈值 : clf.tree_.threshold
不纯度(gini) : clf.tree_.impurity
样本个数 : clf.tree_.n_node_samples
样本分布 : clf.tree_.value
关于节点的预测值
sklearn并没有直接存决策树的类别(概率)预测值,我们需要借助 样本分布 clf.tree_.value,
节点预测类别:样本最多的一类就是节点的预测类别,
节点预测类别的概率:样本占比则是预测概率。
本节展示一个提取决策树信息的实例,具体说明各个信息的使用
决策树实例
# -*- coding: utf-8 -*-
from sklearn.datasets import load_iris
from sklearn import tree
import graphviz
#----------------数据准备----------------------------
iris = load_iris() # 加载数据
#---------------模型训练---------------------------------
clf = tree.DecisionTreeClassifier(random_state=0,max_depth=3) # 初始化决策树
clf = clf.fit(iris.data, iris.target) # 构建决策树
#---------------树结构可视化-----------------------------
dot_data = tree.export_graphviz(clf) # 导出决策树的画图数据
graph = graphviz.Source(dot_data) # 画图
graph # 需要独立运行这一句
#---------------提取模型结构数据--------------------------
children_left = clf.tree_.children_left # 左节点编号
children_right = clf.tree_.children_right # 右节点编号
feature = clf.tree_.feature # 分割的变量
threshold = clf.tree_.threshold # 分割阈值
impurity = clf.tree_.impurity # 不纯度(gini)
n_node_samples = clf.tree_.n_node_samples # 样本个数
value = clf.tree_.value # 样本分布
#-------------打印------------------------------
print("children_left:",children_left) # 打印左节点编号
print("children_right:",children_right) # 打印右节点编号
print("feature:",feature) # 打印分割使用的变量
print("threshold:",threshold) # 打印分割使用的阈值
print("impurity:",impurity) # 打印不纯度(gini)
print("n_node_samples:",n_node_samples) # 打印样本个数
print("value:",value) # 打印样本分布代码运行结果如下:
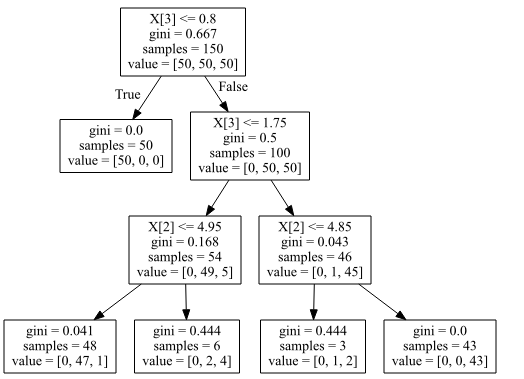
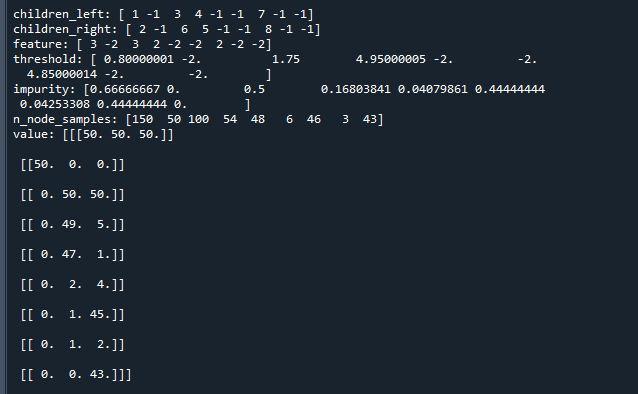
借助决策树拓扑图与输出值对比,可以较容易理解各个数据在树中的意义
提取树结构
树结构信息存在children_left和children_right ,它们记录了左右节点编号
children_left[0] = 1 ,代表第0(根节点)个节点左节点编号为1
children_right[0] = 2 ,代表第0(根节点)个节点右节点编号为2
由上可知,根节点的左节点编号为1,右节点编号为2
左节点1和节点2的子节点去哪找呢,继续代入 children_left和 children_right即可
左节点1的子节点编号:左子节点 children_left[1] = -1,右子节点children_right[1] =-1
-1代表没有子节点(即说明左节点1是叶子节点)
右节点2的子节点编号:左子节点children_left[2]= 3 ,右子节点children_right[2] = 6
....
如此类推,就可以得到整棵决策树的结构
提取节点信息
根据输出的结果,每个节点的信息如下:
第0个节点的信息:
分割变量 :feature[0] = 3
分割阈值 :threshold[0] =0.8
不纯度(gini系数) :impurity[0] = 0.66666667
样本个数 :n_node_samples[0] = 150
样本分布 :value[0] = [50 50 50]
第1个节点的信息:
分割变量 :feature[1] = -2 (-2代表是叶子节点,该值没意义)
分割阈值 :threshold[1] = -2 (-2代表是叶子节点,该值没意义)
不纯度(gini系数) :impurity[1]= 0
样本个数 :n_node_samples[1] = 50
样本分布 :value[1]= [50 0 0]
......
......
如此类推即可
好了,以上就是如何在sklearn中提取决策树规则与节点信息了~
End