本站原创文章,转载请说明来自《老饼讲解-机器学习》www.bbbdata.com
在决策树的实际应用中,我们并不是简单地调用一下sklearn构建一棵决策树,
而是需要一套完整的建模流程,包括数据处理、参数调优、剪枝等等操作,
本文讲述一个决策树建模的完整流程,具体代码实现在《决策树建模完整代码》
本节讲解决策树建模的完整流程
决策树建模-完整流程概述
决策树建模完整流程主要有五个:
1. 数据处理
对数据进行初步处理,使数据符合决策树模型的要求
2. 试探建模极限
试探性建模,粗略估计决策树模型的效果,以及训练误差的极限
3. 参数调优
对模型进行参数调优,得到泛化能力较好的决策树模型
也可以认为这部分是对决策进行预剪枝
4. 后剪枝
对构建好的决策树进行后剪枝,进一步加强模型的泛化能力
5. 模型提取
对决策树进行可视化,以及提取模型的结构,以便线上布署
本节详细描述决策建模过程中的各个步骤
决策树建模-数据预处理
在决策树建模前,需要先将数据处理成符合决策树要求的数据,然后将数据分割为训练、测试数据
一、数据适配预处理
1. 缺失值填充
决策树(CART)不支持缺失值,在建模前需要把缺失数据按业务逻辑处理成非缺失值
备注:有人说决策树支持缺失值,其实说的是C4.5算法,sklearn用的是CART,不要搞混乱了
2. 枚举变量转成数值变量
CART树的每个节点都是判断 变量在阈值的 左边还是右边
因此,它是不支持枚举变量的,需要处理成数值变量,处理方法不在此展开
二、训练、测试数据分割
决策树是一个易于过拟合的模型,需要数据分割为两份:
1. 训练数据集(80%) :用于构建决策树
2. 测试数据集(20%):用于评估决策树的预测效果
在python中可以使用下述语句对数据进行分割:
train_X,test_X,train_y,test_y = train_test_split(X,y,test_size=0.2,random_state=0)
决策树建模-试探模型极限
为什么要试探模型极限
我们建模结果并不总是一直顺利如意,模型的结果可能不理想
效果不理想的原因,可能是数据问题,也可能是模型参数问题
所以,我们要先试探一下用这批数据建模的极限在哪里
如果很差,那就没必要在模型参数上太纠结了,应往数据上找问题
因为参数的调整,仅是让我们往这个极限上靠拢
所以,先试探一下最优模型,能让之后的建模过程心里更有底
试探决策树建模极限的方法
决策树试探极限,我们这里采取的方法是把树分裂到极致,也就是把参数调到极致(即用默认参数)
#--------模型极限试探-----------------------------------
clf = tree.DecisionTreeClassifier(random_state=20)
clf = clf.fit(all_X, all_y)
total_socre = clf.score(all_X,all_y)
clf = clf.fit(train_X, train_y)
train_socre = clf.score(train_X,train_y)
print("\n========模型试探============")
print("全量数据建模准确率:",total_socre)
print("训练数据建模准确率:",train_socre)决策树建模-预剪枝(参数调优)
预剪枝的实际操作方案
建模中,我们需要考虑模型的泛化能力,因此需要设置预剪枝参数,
预剪枝参数怎么设?我这们里采用《参数网格扫描》+《交叉验证方法》进行参数确定
一、什么是参数网格扫描
例如,我们要确定参数max_depth和min_samples_leaf
预设max_depth扫描[3,5,7,9,11,13,15]7个值,min_samples_leaf扫描[1,3,5,7,9]5个值
那么它们的组合共有 5*7=35 种,然后对每组参数进行评估,最后选出最优的参数组合
二、 什么是K折交叉验证评估方法
由于需要评估不同参数下的模型效果,不妨采用《K折交叉验证评估方法》来评估模型效果
K折交叉验证评估方法思想如下:
例如5折交叉验证,则把数据分为5份,训练5轮,每轮训练用1份数据验证,其余4份训练
这样最终每个样本都有预测值,最后把预测值的准确率(或其它指标)作为评估指标
"K折交叉验证评估方法"中评估指标时用的是检验数据,所以它评估的是泛化能力
预剪枝时需要调优的参数
预剪枝时一般调的参数有:
min_samples_leaf :叶子节点最小样本数。
max_depth :树分枝的最大深度
random_state :随机种子
其它不太常用的预剪枝参数则有:
min_samples_leaf :叶子节点最小样本数。
min_samples_split :节点分枝最小样本个数
max_depth :树分枝的最大深度
min_weight_fraction_leaf :叶子节点最小权重和
min_impurity_decrease :节点分枝最小纯度增长量
max_leaf_nodes :最大叶子节点数
criterion:节点不纯度评估函数(gini,entropy)
预剪枝的代码实现
在sklearn中可用GridSearchCV进行K折交叉验证+网络扫描,
主体代码如下
#-------网格扫描最优训练参数---------------------------
clf = tree.DecisionTreeClassifier(random_state=0)
param_test = {
'max_depth':range(3,15,3) # 最大深度
,'min_samples_leaf':range(5,20,3)
,'random_state':range(0,100,10)
# ,'min_samples_split':range(5,20,3)
# ,'splitter':('best','random')
# ,'criterion':('gini','entropy') # 基尼信息熵
}
gsearch= GridSearchCV(estimator=clf, # 对应模型
param_grid=param_test, # 要找最优的参数
scoring=None, # 准确度评估标准
n_jobs=-1, # 并行数个数,-1:跟CPU核数一致
cv = 5, # 交叉验证 5折
verbose=0 # 输出训练过程
)
gsearch.fit(train_X,train_y)
print("\n========最优参数扫描结果============")
print("模型最佳评分:",gsearch.best_score_)
print("模型最佳参数:",gsearch.best_params_)决策树建模-后剪枝
为了进一步加强模型的泛化能力,和增加模型的合理性,
在最后阶段,我们会人工干预,进行后剪枝调优。
打印决策树相关信息
我们先打印出树结构信息、错误样本分布、树拓扑图、CCP路径等信息
1.决策树结构信息
====决策树信息=================
叶子个数: 5
树的深度: 3
特征权重: [0.00277564 0. 0.54604969 0.45117467]
2.错误样本在叶子节点的分布情况
leaf_node num is_err err_rate
4 9 1 0.111111
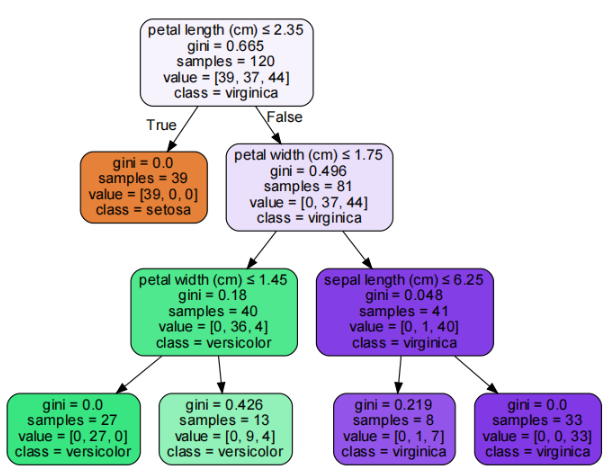
3.决策树可视图
4.打印CCP路径
====CCP路径=================
ccp_alphas: [0. 0.0016 0.0138 0.2587 0.3298]
impurities : [0.0607 0.0624 0.0762 0.3349 0.6648]
它的意思是:
时,树的不纯度为 0.060737,
时,树的不纯度为 0.062414,
时,树的不纯度为 0.076260,
.....
后剪枝
参考CCP路径,我们选择一个可以接受的树不纯度,
找到对应的alpha,使用新的alpha重新训练模型,达到后剪枝效果
例如,我们可接受的树不纯度为0.07626,
则可将alpha设为0.1(在0.01384与0.2587之间)重新训练模型,达到后剪枝效果
后剪枝是最后的优化步骤,我们需要参考以上信息,结合实际业务的特性,对其灵活进行剪枝
End