本站原创文章,转载请说明来自《老饼讲解-机器学习》www.bbbdata.com
正则化是一个解决过拟合较为有效的方法,一般可通过L2正则项来对模型正则化
L2正则项主要通过在损失函数中加入系数的惩罚项,来抑制模型系数过大
本文讲解什么是正则化,什么是正则项,以及常用的L1、L2正则项的具体公式
本节介绍正则化的概念,并通过举例具体说明什么是正则化
什么是正则化
正则化是机器学习中一种常用于预防过拟合的手段
它通过在损失函数中加入正则项来惩罚模型过大的系数,从而勉强过拟合
例如,线性函数最原始的损失函数为:
加入二范正则项的损失函数变为:
这样做的好处是,过大的会让损失函数变得非常大,
在最小化损失函数时,自然就不会取到得大
为什么正则化能防止模型过拟合
为什么加入L2正则项化能防止模型过拟合?
这主要是因为系数过大时模型往往都是过拟合的
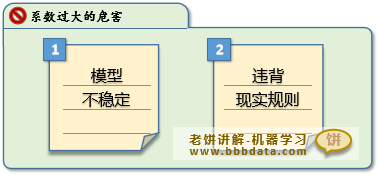
系数过大模型容易过拟合的主要原因有如下:
👉 系数过大会使模型不稳定
👉 过大的系数往往违背真实规则
以线性回归模型举例,当中的W过大时
很容易造成模型的不稳定
例如 y = 10000*x1+10*x2+3 , x1的系数非常大,
导致x1微小的变化都会引起y的极大变化,从而导致模型不稳定,
违反实际规则
现实的业务规则,一般不会出现y与x1成10000倍这么极端关系
所以系数过大时往往是违反背后业务真实规则的,即模型没有如实反映变量与因变量的关系
在误差允许范围内,我们不希望出现极大的系数,或者说,极大的系数本身就是一个数据误导,而非实际规则
因此,模型系数过大往往是不正常的,因此加入正则项来惩罚系数,是令模型"正则化"的一种基本手段
本节列举一些常用的p范正则化函数
P范正则项
p范数是指,机器学习中常用p范来作为正则项
在机器学习中,常见的有L0、L1、L2正则项
L0正则项
L0正则项就是系数中非0系数的个数,L0正则公式如下:
L1正则项
L1正则项就是系数的绝对值之和,L1正则公式如下:
L2正则项
L2正则项就是系数的平方和,L2正则公式如下:
其中,L2正则项是最常用的正则化函数,因为平方项比较方便求导
正则化、正则项与L2正则项
在上文中,我们并没有严格区分正则化、正则项与L2正则项
实际上它们并不相等,而是正则化>正则项>L2正则项
正则化 :正则化通俗来说,就是"正常化"
凡是奔着令模型"正常化"的手段,都称为正则化
正则项 :正则项是指,用于正则化的项
例如在损失函数中加入一项来令模型"更加正常",则称该项为正则项
L2正则项 :L2正则项是一种常用的正则项
L2正则项就是 ,在损失函数中加入L2正则项可以避免模型系数过大
因为"模型疯了"就会过拟合,因此正则化就是希望通过"让模型正常点"来避免模型过拟合
在损失函数中加入正则项是最常用的正则化方法,而L2则是最常用的正则项
因为系数过大时,往往属于一种"不正常"的状况,因此用L2来惩罚系数,可以使模型正常化
由于它们之间强列的从属关系,所以往往正则化默认就指"正则项",而正则项又默认指"L2正则项"
对于初学者,只需要知道L1,L2正则项就可以了,把它当作"正则化"的全部内容也不为过
总的来说,正则化的目的就是避免模型过拟合,增强模型的泛化能力~
End