
本站原创文章,转载请说明来自《老饼讲解-机器学习》www.bbbdata.com
datasets.load_bloan_grp- 小贷分组数据加载函数
datasets.load_bloan_grp用于加载经过分组后的小贷贷款数据,返回样本变量的分组数据与标签数据
完整调用格式如下:
data = br.datasets.load_bloan_grp()返回的数据data如下:

如图所示,数据共2万条,共11列,前10列是变量的分组数据,最后一列是样本标签(is_bad)
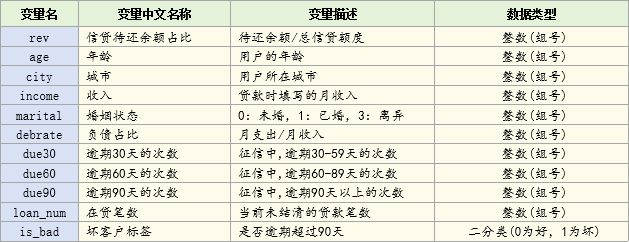
各个字段的含义如下:
load_bloan使用示例如下:
import bbbrisk as br
data = br.datasets.load_bloan_grp() # 加载数据
print('\nbloan_grp数据:\n',data) # 显示数据运行结果如下:
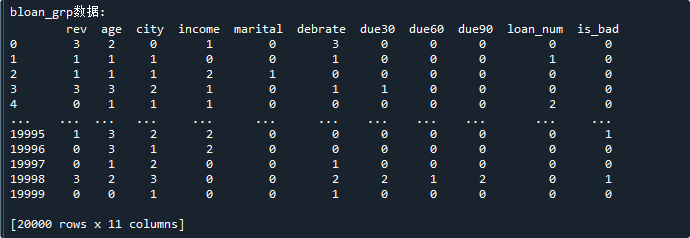
bloan_grp实际是由bloan进行分组后得到,如下:
import bbbrisk as br
#加载数据
data = br.datasets.load_bloan() # 加载数据
x = data.iloc[:,:-1] # 变量数据
y = data['is_bad'] # 标签数据
# 变量的分箱
bin_sets = {
'rev' :[[0,0.1],(['-',0],[0.1,0.37]),[0.37,0.64],([0.64,1.2],[2,'+']),[1.2,2],]
,'age' :[[80,'+'],[60,80],[45,60],['-',45]]
,'city' :[('J','E','I'),'_other',('D','N','S'),('F','P')]
,'income' :[[1000,5000],[5000,9000],(['-',1000],[20000,'+'],None),[9000,16000],[16000,20000]]
,'marital':[1,0,2]
,'debrate':[([0,0.1],[850,'+']),([0.1,0.5],[5,850]),([0.5,0.8],0),[0.8,5]]
,'due30' :[0,1,2,(3,4),[4,'+']]
,'due60' :[0,1,2,[2,'+']]
,'due90' :[0,1,[1,'+']]
,'loan_num':[[3,'+'],(2,3),1,0]
}
x_grp,bin_dict = br.encode.grp.to_grp(x, bin_sets) # 将bloan数据转换为组号
print('\nbloan_grp数据:\n',x_grp) # 显示数据运行结果如下:
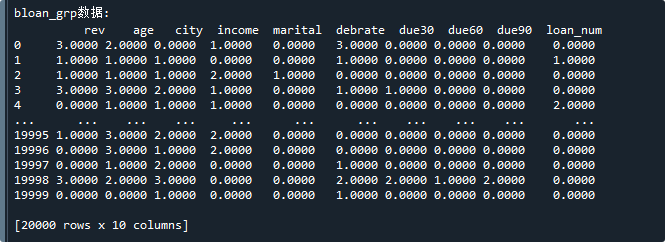
可以看到,它与直接加载bloan_grp数据是一样的
好了,以上就是datasets.load_bloan函数的使用方法了~
End