本站原创文章,转载请说明来自《老饼讲解-深度学习》www.bbbdata.com
GoogLeNet-inception-V2一文除了改进inception模型,还提出了著名的BN批归一化
因此GoogLeNet-inception-V2的原文是CNN学习中的一篇经典论文,
本文讲述GoogLeNet-inception-V2原文中的inception-V2模型及其相关训练方法
本节介绍GoogLeNet-Inception-V2模型的背景和核心内容等等
GoogLeNet-Inception-V2简介
自2014年提出GoogLeNet(V1)之后 ,谷歌公司的Sergey Ioffe和Christian Szegedy在2015年又提出了GoogLeNet-Inception-V2模型
原文的主题并非是提出Inception-V2模型,原文的核心内容是提出BN批归一化层来加速深度学习中神经网络的训练,
但为了说明BN的加速效果,原文在GoogLeNet-V1中加入BN层,从而演变出GoogLeNet-Inception-V2模型,
通过GoogLeNet-Inception-V1与V2(加入了BN层)的效果对比,以此来说明BN(批归一化)层的意义与效果
备注:GoogLeNet-Inception-V2同时也对V1的结构也进行了改进及优化,同样,对Inception模块也进行了修改
总的来说,在GoogLeNet-Inception-V2的原文一共主要贡献了三个比较具有价值的内容:
👉1. 批归一化(BN层)
👉2. Inception-V2模块
👉3. GoogLeNet-Inception-V2模型
其中,BN层-批归一化是最具贡献力的内容,目前它已经是CNN的通用技术之一
GoogLeNet-inception-V2原文:《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift》
本节介绍inception-V2模型的核心模块和核心模块的结构
Inception-V2核心模块介绍
Inception-V2模型在inception-V1模型的基础上引入两个核心模块
👉1. inception-V2模块
👉2. BN批归一化层
在学习Inception-V2模型之前,我们先了解这两个模块分别是什么
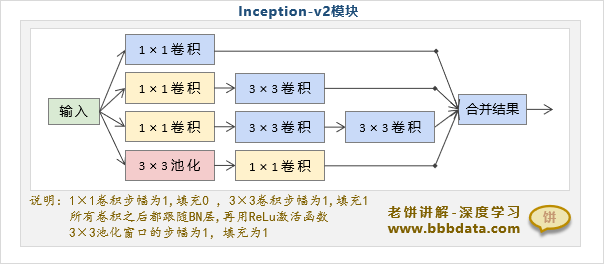
1.Inception-V2模块结构
Inception-V2模块与Inception-V1模块几乎没有区别,
V2仅是参考了VGG的小卷积思想,把V1中的5×5卷积层替换成两个3×3的卷积层
Inception-V2模块的具体结构如下:
2.BN批归一化
BN(Batch Normalization)批归一化是Inception-V2原文中的核心内容,
它通过归一化来解决训练中协变量偏移问题,从而加速多层神经网络的训练
由于BN的效果显著,目前已成为深度学习中的通用技术
因此作为独立文章介绍,详细见:《BN批归一化算法》
GoogLeNet-Inception-V2卷积神经网络-模型结构
GoogLeNet-inception-V2模型由V1修改得到
inception-V2的网络模型具体如下
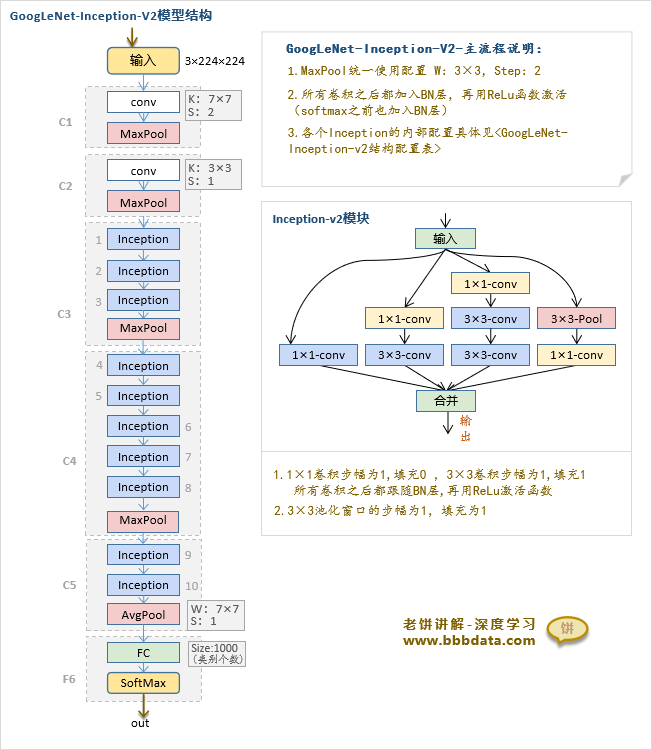
inceptionV2相对V1网络结构的修改如下
模块修改:
1.inception模块的修改:使用了Inception-V2模块(用两个3×3替代V1的5×5)
2.归一化模块的修改:用BN模块替代了LRN
结构与配置修改:
1.所有非线性函数之前加入了BN层(并去除了C1、C2层的LRN)
2.C2层去掉了1×1的降维卷积
3.C3层增加了一个inception
4.Inception内部有部分使用了avg-pool(v1中全用max-pool)
5.修改了各个Inception的输出通道配置
备注:4、5点的修改在结构图中并无体现,可以参考下小节的模型配置表
GoogLeNet-Inception-V2卷积神经网络-模型配置与运算
GoogLeNet-inception-V2的具体配置与运算流程如下:
本节讲解inception-V2的训练方法
GoogLeNet-Inception-V2的训练
inception-V2相对V1最主要的优势提升学习速度,
它离不开配套的训练方法(主要是加入BN后的相关训练措施),
GoogLeNet-Inception-V2-原文的训练方法如下
训练方法
训练方法:带动量的随机梯度下降
批大小 :32
训练措施
原文在训练过程采取的措施:
1. 尽量提高学习率
原文的初始学习率为0.045
2. 提高降低学习率的频率
原文共下降了6次学习率
3. 删除DropOut
4. 降低L2正则化
原文将原L2正则化系数降低了5倍
5. 更彻底洗牌数据
本节附加展示inception-V2原文中的一些内容,包括原文中的配置和一些实验等等
inception-V2模型-原文中的配置表
原文中inception-V2模型的配置表如下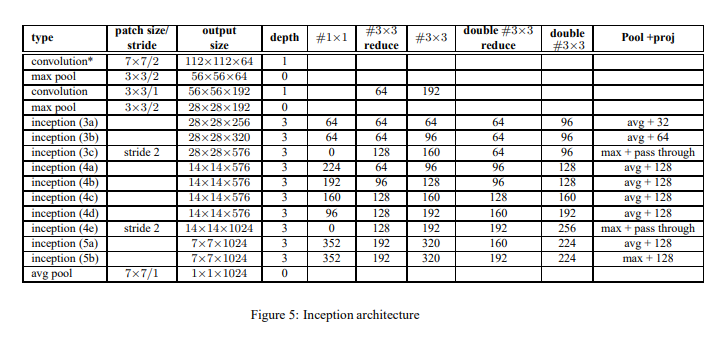
各列的意义如下 :
type:模块类型
patch size/stride:卷积、池化的核、步幅配置,inception该列指的是紧随其后的池化层的步幅
output size: 输出的尺寸
depth:模块带权重参数的层数
#1×1 :Inception内部1×1卷积层的输出通道数
#3×3 reduce :Inception内部3×3卷积层之前的1×1降维卷积层的输出通道数
#3×3 :Inception内部3×3卷积层的输出通道数
double #3×3 reduce :Inception内部双层3×3卷积层之前的1×1降维卷积层的输出通道数
double #3×3 :Inception内部双层3×3卷积层的输出通道数(如果是56,代表两个3*3的都是56)
pool+proj :Inception内部池化层的池化方式,及之后的1×1降维卷积层的输出通道数(pass through代表不用降维卷积层)
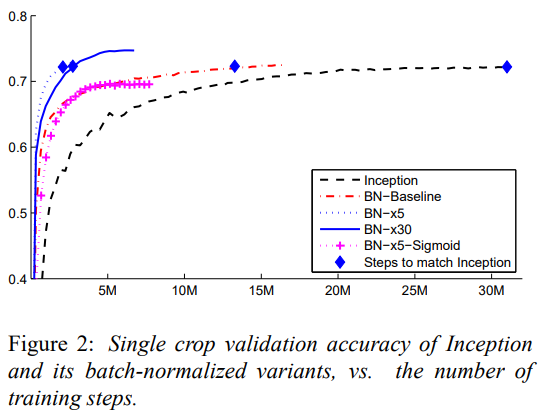
原文中关于inception-V2模型的实验
原文做了5种不同的组合来测试BN层和相关训练措施对Inception模型的提升效果
5种组合的实验效果如下图所示:
5个模型基于本文所述的模型,分别采用的调整措施如下:
1. Inception :初始学习率0.0015,不加BN层
2. BN-BaseLine:初始学习率0.0015
3. BN-x5 :初始学习率0.0075,采取训练措施
4. BN-x5- sigmoid:初始学习率0.0075,采取训练措施,将ReLu替换为Sigmoid
5. BN-x30 :初始学习率0.045,采取训练措施
这里的后缀5、30代表的是相对BaseLine学习率的倍数
其中,训练措施指的是:
1.尽量提高学习率
2.加速降低学习率
3.删除DropOut
4.降低L2正则化(降低5倍)
5.更彻底洗牌数据
总结:Inception-V2与V1的主要区别
总的来说,Inception-V2就是基于V1加入了BN层及修改了inception模块
GoogLeNet-Inception-V2整体的效果比V1训练更快,效果更好
GoogLeNet-Inception-V2修改的主要内容如下:
1. 对模型结构进行了相关修改
调整了卷积网络整体结构并修改了Inception模块
2. 加入BN层进行提速
模型在非线性函数之前加入了BN层,并提高了学习率,删除了DropOut
整体效果的区别就是,V2的训练更快,效果更好
以上就是GoogLeNet-Inception-V1模块的全部内容了~
End