本站原创文章,转载请说明来自《老饼讲解-深度学习》www.bbbdata.com
本节介绍研究深层全连接神经网络的意义,以及所需要了解的内容
深层全连接神经网络的研究目的
虽然三层的全连接神经网络很好用,但往往并不能满足图片、文本预测的训练,从而诞生了CNN和RNN等方法
CNN还是RNN都属于全连接神经网络的拓展,由于它们将神经网络网络拓展到非常深的层数,统称为深度学习,
虽然CNN、RNN等深度学习常用模型与深层全连接神经网络不同,但它们与深层全连接神经网络的性质相似
因此,在CNN、RNN某些方面的研究上,往往都先基于简洁的深层全连接神经网络,再将得到的结论进行迁移
总的来说,虽然很少使用深层全连接神经网络(深层MLP),但理论上会经常研究它,
研究深层全连接神经网络的目的并非为了使用它,而是为了将相关研究结果拓展到CNN、RNN上
深度学习中的两个基础研究成果
对于初学习,几须了解的关于深度学习的基础知识包括以下两个:
👉1. 深度学习中的梯度爆炸与梯度消失
梯度爆炸与梯度消失是深层神经网络训练困难的主要原因,从而很多改进都是针对两者而诞生
因此了解梯度爆炸与梯度消失才能理解深度学习一些技术出现的原因
👉2. 激活函数-ReLu
在深度学习中不再使用tanh函数作为激活函数,而是使用ReLu函数
主要因为tanh会加剧梯度爆炸与梯度消失,所以深度学习中基本使用ReLu函数,减缓梯度爆炸与梯度消失
本节介绍深度学习上的梯度爆炸与梯度消失是什么
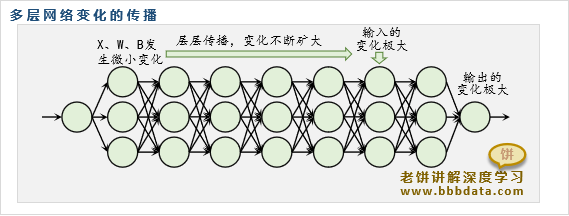
深度学习训练上的困难-梯度爆炸与梯度消失
深层神经网络,看似只加多了几层,但一旦层数足够深,就迎来了两方面的困难:
1.网络前馈输出的不稳定
由于多层的传播,输入的微小变化,经过层层传播与扩大,很容易会使输出层的值引起极大的变化
从背景意义来说,x和y之间不应该这么跌宕,例如图片,不可能因为x变化一个象素,y就极大变化
如果给深层神经网络随便取一个解,往往所构成的都是这种非常跌宕模型,也即非常糟糕的模型
这意味着在整个解空间中,充斥着非常多低质量解,一不小心就踩上雷,因此网络对解的要求更加苛刻
2.网络梯度后馈的不稳定-梯度爆炸与梯度消失
由于训练时需要使用链式法则,将梯度后馈式层层传播,
在网络很多层时,梯度层层传播很容易出现梯度绝对值不断缩小(梯度消失)或不断扩大(梯度爆炸)
当梯度趋于0时,将无法更新权重,当梯度极大时,则会引起迭代过大、训练上的不稳定
而事实上,在多层网络中,很容易出现梯度消失和梯度爆炸,也就是说多层网络的训练往往总是出现各种困难
本节介绍深度学习上主要使用的激活函数-ReLu与Leaky-ReLu
深度学习中的激活函数
深度学习中较常用的激活函数为ReLu与Leaky-ReLU函数
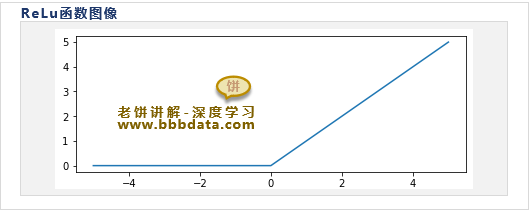
ReLu激活函数
ReLu激活函数的公式如下:
ReLu函数的与图象如下:
ReLu函数的生物思想就是,让神经元要么干活,要么不干活,也就是让神经元稀疏化
自从把激活函数从sigmoid改为ReLu后,深层网络的训练效果就是好很多,所以基本都是用ReLu函数作为激活函数
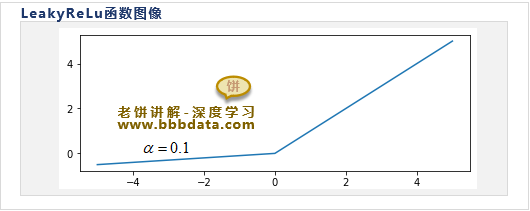
Leaky-ReLU激活函数
Leaky-ReLU激活函数的公式如下:
或者
Leaky-ReLu函数的与图象如下:
Leaky-ReLU是对ReLu的修改,ReLU函数在<0时导数为0,
Leaky-ReLU企图让ReLu的导数不为0,希望这样能加速训练,但实际应用中并没有十分明显的效果,
但不管怎么样,Leaky-ReLU的修改对于ReLu来说有益无害,所以Leaky-ReLU也是一个常用的激活函数
深度学习为什么一般不用S型激活函数
sigmoid、tanh等S型激活函数在深层网络中是非常糟糕的激活函数,
虽然没有非常严谨的理论证明,但在各种实际应用中sigmoid之类的S型函数的表现的确非常差
为什么sigmoid之类的函数的表现会这么差?主要还是难以训练,在理论上可以如下简单理解:
1. 从梯度爆炸与梯度消失理解sigmoid激活函数导致训练困难的原因
多层网络经过层层传播,很容易令sigmoid处于饱和状态,此时sigmoid的梯度近乎为0
而梯度公式是一个链式的形式,当多个sigmoid的梯度都近乎为0时,整体梯度就会近乎为0
也就是sigmoid作为激活函数时,很容易出现梯度消失,训练就极为缓慢
2. 从模型敏感度理解sigmoid激活函数导致训练困难的原因
sigmoid之类的函数,很容易引起神经元死亡,如果某层的神经元全部死亡,那么输出就变成了枚举值
当模型处于枚举值状态时,输出对于前层的值的微小的变动要么是保持不变,要么是突变,
因此,也就会导致:损失函数对于前层的权重的梯度要么很大,要么为0,这就造就了难以训练
总的来说,sigmoid之类的S型函数在深度学习的实践中就是很难训练出一个好的模型,很少用sigmoid作为激活函数
End