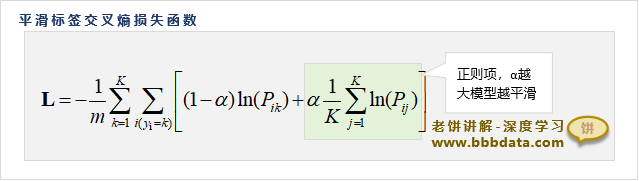本站原创文章,转载请说明来自《老饼讲解-深度学习》www.bbbdata.com
平滑标签交叉熵损失函数属于交叉熵损失函数的一种改进,它出自inception-V3模型的原文
本文讲解平滑标签-交叉熵损失函数的计算公式,以及讲解它的意义,通过本文可以具体地掌握平滑标签-交叉熵损失函数
本节展示平滑标签交叉熵损失函数的具体计算公式
交叉熵损失函数-平滑标签形式
平滑标签-交叉熵损失函数出自论文《Rethinking the Inception Architecture for Computer Vision》
它在交叉熵损失函数的基础上,降低对样本标签的信任程度,属于交叉熵损失函数的一种正则化改进
平滑标签交叉熵损失函数的计算公式如下:
其中
:样本个数
:类别个数
:第i个样本的真实类别
:第i个样本属于第k个类别的预测概率
:平滑系数,一般设为0.1
本节讲解应该如何理解平滑标签交叉熵损失函数
包括平滑标签交叉熵损失函数的推导、讲解以及平滑标签的意义
平滑标签交叉熵损失函数-公式解读
交叉熵损失函数与平滑标签交叉熵-公式对比
交叉熵损失函数与平滑标签交叉熵的公式分别如下:
交叉熵损失函数公式为:
平滑标签交叉熵公式为:
可以看到,平滑形式只是将改为了
平滑标签交叉熵损失函数的解读
我们知道,是知道第i个样本是k类时,所带来的信息量(震惊程度)
如果样本的采样标签并不准确,我们不信任采样标签,那么样本可能是任意一个类别
则在知道样本真实类别时,所带来的信息量期望为
平滑标签将“相信采样标签”与"不相信采样标签"两种情况进行加权,作为第i个样本的信息量
总的来说,平滑标签交叉熵就是在交叉熵的基础上,考虑了采样不准确,不信任采样标签的情况
平滑标签交叉熵损失函数的意义
平滑标签交叉熵损失函数考虑了采样不准确的场景,降低样本标签的“自信”,
这样做是为了使模型更加平滑,增强模型的泛化能力
也就是说,平滑标签交叉熵损失函数相当于交叉熵损失函数的一种正则化形式
其中是对交叉熵损失函数所引入的正则项
好了,平滑标签交叉熵损失函数就介绍到这里
.
End