本站原创文章,转载请说明来自《老饼讲解-深度学习》www.bbbdata.com
VGGNet是牛津大学计算机视觉组(Visual Geometry Grouop)和Google DeepMind公司的研究员在2014年一起研发的深度卷积神经网络
VGGNet通过使用3×3的小卷积替代了传统的大卷积,从此开启了小卷积的应用之路,在卷积神经网络中意义深重
本文讲解VGGNet是怎么来的,VGGNet的核心思想,及VGGNet的相关深度模型实验,从本文可以初步了解VGGNet是怎么一回事
本节简单介绍VGGNet是什么、VGGNet怎么来的、VGGNet的思想是什么
VGGNet卷积神经网络简介
VGGNet与VGG的深度实验简介
AlexNet扬名后,大伙都在AlexNet上进行改进来研究新的卷积神经网络
其中,由VGG(Visual Geometry Group&Google DeepMind )在2014年推出的VGGNet取得较为显著的成果
VGGNet在ImageNet大型视觉识别挑战ILSVRC2014中定位任务第一名和分类任务第二名
VGG对卷积神经网络改进的主要思路是用几个小核卷积层,替代大核卷积层
也就是说,AlexNet的每一个卷积层,都被几个小核卷积层代替,这意味着网络的深度更深
VGG在AlexNet的基础上,由浅到深尝试不同的配置方案所带来的效果
直到网络变为19层时,再加深就没有效果了
整个实验过程,VGG一共做了六组的模型(A、A-LRN、B、C、D、E)
最终的D模型(16层)和E模型(19层)效果最好(两个模型后来又被称为VGG16和VGG19),
VGG将上述模型投入2014年ILSVRC竞赛,获得第二名,从此VGGNet被广泛认可
总结:什么是VGGNet
总的来说,VGGNet系列就是由VGG团队在AlexNet的基础上进行的一系列对卷积神经网络不断加深的实验得到的
整个实验过程共有6个模型,其中D模型VGG-16(16层)和E模型VGG-19(19层)是6个模型中最有价值的两个模型
VGGNet原文:VGGNet原文为《Very Deep Convolutional Networks for Large-Scale Image Recognition》
本节介绍VGGNet进行的一系列深度实验的思想和模型
VGG的核心思路:小卷积替代大卷积
VGG的核心思想:用小卷积替代大卷积
VGG的核心思路是用多个小核卷积层替换大核卷积层
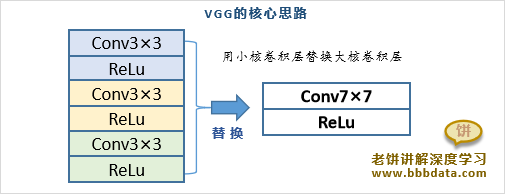
例如,用三个3×3的卷积层替换一个7×7的卷层,如下:
用小卷积替代大卷积的好处
用三个3×3的卷积层替换一个7×7的卷层的好处如下:
👉1. 替换前后的接受野是一致的
一层3×3卷积层的接收野是3,两层之后的接收野就是5,三层的收接野就是7
这样与一个7×7的卷积层的接收野是一致的
👉2. 三层小核卷积层的参数更少
假设卷积核的输入和输出都是C个通道
三个3×3卷积层的权重参数个数为:
单个7*7卷积层的权重参数个数为:
可以明显看到,三个小核卷积层的总参数更少
👉3.三层小卷积核的拟合能力更强
由于卷积层后会跟随一个非线性激活函数(不妨设为ReLu)
单个大卷积层的输出对原始X进行了一次非线性转换
而三个小卷积层的输出对原始X进行了三次非线性转换
明显地,三层结构拥有三次非线性变换,它的拟合能力更强
总的来说,就是用多层小核换单层大核,不仅保持了原有的视野,而且参数更少,拟合能力更强
VGG的6组实验模型
下面介绍VGG的6组实验模型是如何设计的
VGG的6组实验模型的设计
VGG根据以上思路,先将ALexNet的大核卷积层改为多个小核卷积层,然后不断给网络继续添加小核卷积,
这个过程一共做了6组模型进行实验,先看6组模型的实验参数表:
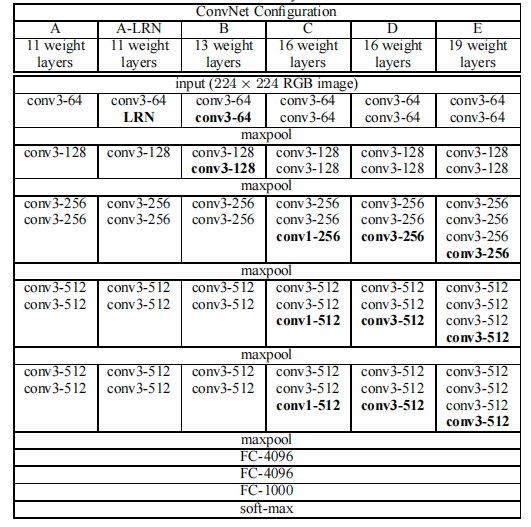
✍️关于配置中的说明:
conv3-128:指的是128个3×3×k的卷积核(k与输入的通道数保持一致),
其中,卷积填充为1,步幅为1
maxpool:指的是使用窗口Size为2×2、步幅为2的Max池化方法
VGG的6组模型的解读
整个实验是对AlexNet的改进,所以大结构和输入、输出与AlexNet保持一致
👉关于结构:6组模型都保持AlexNet的5大池化层,3个全连接层的结构,
只是将AlexNet卷积层中的大核换成几个小的卷积核层
👉关于输入:输入统一是224×244×3(RGB)的图像(与AlexNet保持一致)
VGGNet六组模型的设计思路
VGGNet六组模型的设计思路如下:
1. A模型:A模型是整个实验中的Base模型
它只是将AlexNet中的卷积层用几层小核卷积层进行替换(总层数为11)
1、2卷积层换成一个Size为3的小核卷积层
3、4、5层换成两个Size为3的小核卷积层
2. A-LRN模型:在A的C2层加入LRN(局部归一化)得到模型B,发现没什么用(总层数为11)
3. B模型:抛弃LRN,直接在A上加深C1,C2层,(总层数为13)
4. C模型:在C模型基础上,在C3、C4、C5上各增加一个核Size为1的卷积层(总层数为16)
5. D模型:在C模型基础上,在C3、C4、C5上各增加一个核Size为3的卷积层(总层数为16)
6. E模型:在C模型基础上,在C3、C4、C5上各增加两个核Size为3的卷积层(总层数为19)
最后发现,D和E的效果不错,但如果再加深效果就不好了
✍️老饼点评
1. VGGNet的小核亮点
可以看到,从模型A到模型E,模型的深度由11层到19层
但参数却没有过多的增长,所以用小核层换大核层确实是个很好的方法
2. 该关注VGGNet的哪些模型
D和E又根据层数,被后人称称为VGG16和VGG19
也就是说,除了D和E,其它的只是VGG实验品,不用过于关注
VGGNet实验中的一些配置解释
1.为什么使用3*3形式的卷积层?
VGGNet中大量采用"SIze3×3的卷积核(填充为1,步幅为1)"
为什么使用这样的卷积核呢?原因如下:
1. 先说卷积核Size为什么是3×3:
这是因为VGG的核心就是要用小核换大核,所以核的Size要尽量的小
而能综合周边(上下左右)信息的卷积核Size最小就是3×3,因此采用Size=3×3的卷积核
2. 其次是为什么使用"填充为1,步幅为1":
填充为1步幅为1是为了保持卷积前后的图片Size不变
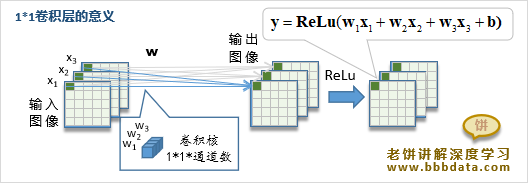
2.为什么使用形式的1×1卷积层
可以看到,在VGGNet的实验中,时不时会加入一些核Size为1×1的卷积层
为什么要加入这些1×1的卷积层进行尝试呢?1×1的卷积层的意义是什么?
由于1×1的卷积核每个通道只有1个元素,
所以它相当于将之前图像的各个通道加权合并为一个新的图像
如下图所示:

注意到实验中所用的1×1卷积核个数与输入通道一致,并且随后会被ReLu
因此整层的意义是将原图像的n个通道线性合并成新的n个通道,并进行非线性ReLu影射
总的来说,1×1卷积层的意义就是将原图像进行一次Size不变的非线性层转换
备注: 1×1卷积层只是模型C的一种尝试,VGG16、19中并不使用
3.关于卷积输出通道个数的设置
需要注意的是,VGGNet中卷积的输出通道个数的设置是有规律的
对于每一个大层,卷积输出通道个数翻倍递增,以64为初始值,512为最大值
本节介绍VGGNet实验中各个模型的效果
VGGNet的实验结果
VGG各个模型的识别效果
VGGNet各个模型用于ImageNet(LSVRC-2014的比赛图片)图片类别识别的效果如下
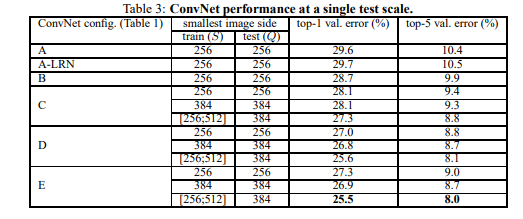
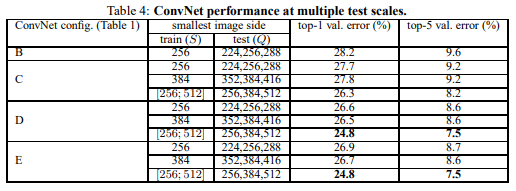
说明:之所以有两张结果表,是因为VGGNet的实验中除了拓展深度,
还配合了不同的数据处理、模型预测等方法的对比等等
关于VGGNet的数据处理、模型评估的具体方法见《VGG16模型及训练》
VGG各个模型的识别效果-表格说明
两个表的区别
VGG实验中使用了两种模型评估方法:单尺寸评估、多尺寸评估
表3是单尺寸评估时的结果,表4是多尺寸评估时的结果
各列的含义
第一列(ConvNet cinfig) :模型名称
第二列(smallest image side) :模型参数,S、Q是数据处理时的参数
第三列(top-1 val.error%) :评估指标,模型的top-1错误占比
第三列(top-5 val.error%) :评估指标,模型top-5的错误占比
PASS:top-1 和 top-5的含义
top-1 error% 是指模型预测概率最高的5个类别,如果都不是真实类别,则判为模型判断错误
top-5 error% 是指模型预测概率最高的5个类别,如果都不是真实类别,则判为模型判断错误
VGG各个模型的识别效果-结果解说
可以看到,单尺寸评估时,D模型和E模型的top-5 error基本只有8%-9%,而B、C模型的效果为9%-11%
对于多尺寸评估,D模型和E模型的top-5 error基本只有7%-9%,而B、C模型的效果为9%-10%
总的来说,D、E模型选择多尺寸评估方法时,效果是最好的,最佳的模型top-5 error只有7.5%
因此,较推荐使用D模型(VGG16)和E模型(VGG19)
End