本站原创文章,转载请说明来自《老饼讲解-深度学习》www.bbbdata.com
深度学习常用的激活函数除了ReLu、LeakyReLu、Sigmoid、tanh等之外,还有许多其它激活函数
本文展示pytorch所提供的所有激活函数,包括激活函数的图像、计算公式、和pytorch的API等
本节介绍pytorch中提供的激活函数以及它们的图像
pytorch深度学习-激活函数简介
在pytorch中提供了各种激活函数,包括如下:
ELU、Hardshrink、Hardsigmoid、Hardtanh、Hardswish、LeakyReLU、LogSigmoid、
MultiheadAttention、PReLU、ReLU、ReLU6、RReLU、SELU、CELU、GELU、Sigmoid、
SiLU、Mish、Softplus、Softshrink、Softsign、Tanh、Tanhshrink、Threshold、GLU、
Softmin、Softmax、Softmax2d、LogSoftmax、ADAPTIVELOGSOFTMAXWITHLOSS
各个函数的详细说明: https://pytorch.org/docs/stable/nn.html#non-linear-activations-weighted-sum-nonlinearity
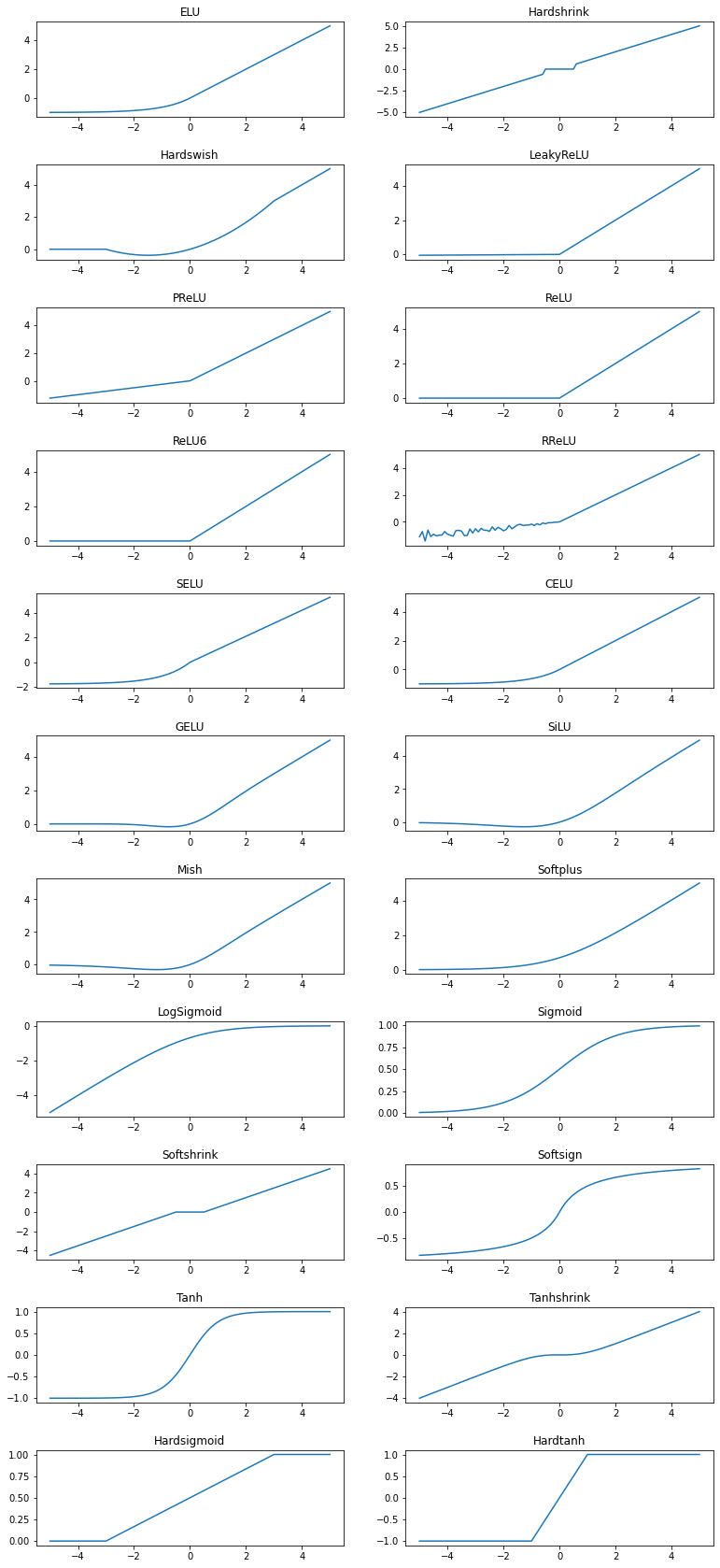
pytorch深度学习-激活函数图像
✍️备注:上述图象中不包括MultiheadAttention、Threshold、GLU三个激活函数
本节介绍激活函数的公式以及pytorch中激活函数API
ELU
torch.nn.ELU(alpha=1.0, inplace=False)
Hardshrink
torch.nn.Hardshrink(lambd=0.5)
Hardsigmoid
torch.nn.Hardsigmoid(inplace=False)
Hardtanh
torch.nn.Hardtanh(min_val=- 1.0, max_val=1.0, inplace=False, min_value=None, max_value=None)
Hardswish
torch.nn.Hardswish(inplace=False)
LeakyReLU
torch.nn.LeakyReLU(negative_slope=0.01, inplace=False)
或者
LogSigmoid
torch.nn.LogSigmoid(*args, **kwargs)
MultiheadAttention
torch.nn.MultiheadAttention(embed_dim
, num_heads
, dropout=0.0
, bias=True
, add_bias_kv=False
, add_zero_attn=False
, kdim=None
, vdim=None
, batch_first=False
, device=None
, dtype=None)
其中
PReLU
torch.nn.PReLU(num_parameters=1, init=0.25, device=None, dtype=None)
或者
ReLU
torch.nn.ReLU(inplace=False)
ReLU6
torch.nn.ReLU6(inplace=False)
RReLU
torch.nn.RReLU(lower=0.125, upper=0.3333333333333333, inplace=False)
SELU
torch.nn.SELU(inplace=False)
其中,
CELU
torch.nn.CELU(alpha=1.0, inplace=False)
GELU
torch.nn.GELU(approximate='none')
其中是高斯分布的累积分布函数
用tanh来近似时,GELU的计算公式为
Sigmoid
torch.nn.Sigmoid(*args, **kwargs)
SiLU
torch.nn.SiLU(inplace=False)
Mish
torch.nn.Mish(inplace=False)
Softplus
torch.nn.Softplus(beta=1, threshold=20)
Softshrink
torch.nn.Softshrink(lambd=0.5)
Softsign
torch.nn.Softsign(*args, **kwargs)
Tanh
torch.nn.Tanh(*args, **kwargs)
Tanhshrink
torch.nn.Tanhshrink(*args, **kwargs)
Threshold
torch.nn.Threshold(threshold, value, inplace=False)
GLU
torch.nn.GLU(dim=- 1)
其中,a是矩阵的前半部分,b是矩阵的后半部分,结果是原矩阵的一半
Softmin
torch.nn.Softmin(dim=None)
Softmax
torch.nn.Softmax(dim=None)
Softmax2d
torch.nn.Softmax2d(*args, **kwargs)
对图片进行softmax,
当输入为单张图片(C,H,W)时,对每个通道各自进行softmax,
当输入为多张图片(N,C,H,W)时,对每张图片每个通道各自进行softmax
# 通过下面的例子可以了解Softmax2d是怎么回事
torch.manual_seed(99)
m = torch.nn.Softmax2d()
input = torch.randn(3,4,5)
output = m(input)
n = output.numpy()
n.sum(axis=0)LogSoftmax
torch.nn.LogSoftmax(dim=None)
ADAPTIVELOGSOFTMAXWITHLOSS
torch.nn.AdaptiveLogSoftmaxWithLoss(in_features
, n_classes
, cutoffs
, div_value=4.0
, head_bias=False
, device=None
, dtype=None)
类别非常多时(比如上百万个类),Softmax的高效实现
附件:绘图所有激活函数图像的代码
import torch
import matplotlib.pyplot as plt
import math
x = torch.arange(-5,5.1,0.1)
mds = {'ELU':torch.nn.ELU()
,'Hardshrink':torch.nn.Hardshrink()
,'Hardswish':torch.nn.Hardswish()
,'LeakyReLU':torch.nn.LeakyReLU()
,'PReLU':torch.nn.PReLU()
,'ReLU':torch.nn.ReLU()
,'ReLU6':torch.nn.ReLU6()
,'RReLU':torch.nn.RReLU()
,'SELU':torch.nn.SELU()
,'CELU':torch.nn.CELU()
,'GELU':torch.nn.GELU()
,'SiLU':torch.nn.SiLU()
,'Mish':torch.nn.Mish()
,'Softplus':torch.nn.Softplus()
,'LogSigmoid':torch.nn.LogSigmoid()
,'Sigmoid':torch.nn.Sigmoid()
,'Softshrink':torch.nn.Softshrink()
,'Softsign':torch.nn.Softsign()
,'Tanh':torch.nn.Tanh()
,'Tanhshrink':torch.nn.Tanhshrink()
,'Hardsigmoid':torch.nn.Hardsigmoid()
,'Hardtanh':torch.nn.Hardtanh()
# ,'MultiheadAttention':torch.nn.MultiheadAttention()
# ,'Threshold':torch.nn.Threshold()
# ,'GLU':torch.nn.GLU()
}
figure = plt.figure(figsize=(13, 30))
col = 2
row = math.ceil(len(mds)/col)
t = 0
for key in mds:
t = t + 1
figure.add_subplot(row,col, t)
plt.title(key)
y = mds[key](x).detach().numpy()
plt.plot(x,y)
plt.subplots_adjust(wspace=0.2,hspace=0.5)
plt.show()好了,以上就是pytorch深度学习中各个激活函数的公式与图像了~
End