本站原创文章,转载请说明来自《老饼讲解-深度学习》www.bbbdata.com
CNN是基于BP神经网络应用于类别预测进行的模型改进,因此BP神经网络应用于类别预测是CNN的基础知识
本文讲解类别预测问题是什么、BP神经网络应用于类别预测时的模型结构、损失函数以及训练方法
通过本文可以了解BP神经网络是怎么解决类别预测问题的,以及它与BP应用于数值预测时的区别
本节讲解BP神经网络应用于分类时的模型结构
什么是分类问题
分类问题也称为模式识别问题,就是预测样本所属的类别
分类问题的每个训练样本都对应一个类别标签,代表该样本属于哪个类别
分类问题的类别表示:one-hot向量
在机器学习中,一般使用one-hot向量来表示样本的类别,
one-hot向量的格式与含义如下:
one-hot向量的长度与类别个数一致,只有一个元素的值为1,其余为0,
one-hot向量第i个元素为1时,就表示样本为第i类
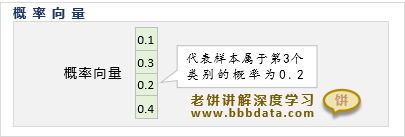
分类问题的模型输出:概率向量
分类问题可以直接输出样本的所属类别,但更一般地,是输出样本属于每个类别的概率,
所以分类问题的模型输出的是一个概率向量,如下:
概率向量的第i个元素代表样本属于第i个类别的概率
BP神经网络模式识别-网络结构
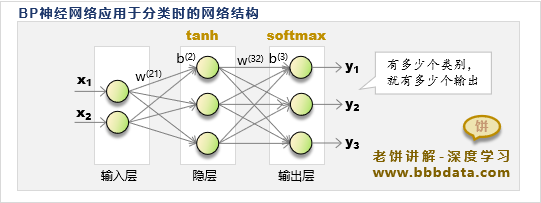
BP神经网络应用于分类时的结构
BP神经网络应用于分类时,一般用的仍然是三层结构,相对特别的有如下两点:
1. 有多少个类别,网络就有多少个输出
2. 网络的输出进行softmax转换,把网络的结果归一化为类别的概率
BP神经网络应用于分类时的具体结构示例如下:
如图所示,第一层是输入层,第二层是隐层,第三层是输出层
输出层的神经元个数与类别个数一致,并且输出层加入了softmax函数
其中,softmax的计算公式如下:
也就是对最后一层的每个输出值先进行指数转换,再进行归一化
本节讲解BP神经网络用于模式识别时,所使用的损失函数与训练方法
BP神经网络模式识别-网络训练
BP神经网络进行类别预测时的损失函数
BP神经网络应用于模式识别时,损失函数一般使用交叉熵损失函数
交叉熵损失函数计算公式-定义形式:
其中, :样本个数
:模型判断第i个样本属于类别k的概率,k是样本的真实标签
BP神经网络进行类别预测时的训练算法
BP神经网络用于类别预测时的训练算法与应用于数值预测时是一致的,
只需要使用梯度下降就可以了,只是其中使用交叉熵损失函数来计算梯度而已
梯度下降算法的流程如下:
一、先初始化一个解
二、迭代
1. 将解往误差函数的负梯度方向更新
这里的梯度计算使用交叉熵损失函数来计算
2. 判断是否满足退出条件,如果满足,则退出迭代
好了,关于BP神经网络应用于类别预测的算法原理就讲到这里了~
End