本站原创文章,转载请说明来自《老饼讲解-深度学习》www.bbbdata.com
pytorch构建模型的强大在于它可以通过构建各种简单模块,来组合出非常复杂的深度学习模型
本文讲解pytorch的模块构建、pytorch自带的模块,以及如何将模块组合出目标模型
通过本文可以了解,如何使用pytorch构建一个带模块的模型,以及如何使用pytorch自带的模块
本节展示pytorch中如何定义一个模块并在模型中使用
pytorch带模块的模型-示例
下面仍然是使用pytorch实现一个三层的BP神经网络,在本例中我们在模型中引入了子模块的概念
具体示例如下:
import torch
from torch import nn
# -----------定义模型-----------
# 定义线性层模块
class Liner(nn.Module):
def __init__(self,in_num,out_num):
super(Liner, self).__init__()
self.w = nn.Parameter(torch.randn(in_num,out_num)) # 定义模块参数w1
self.b = nn.Parameter(torch.randn(1,out_num)) # 定义模块参数b1
def forward(self, x):
y = x@self.w+self.b
return y
# 定义模型
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.L1 = Liner(2,3) # 定义第一个线性层
self.L2 = Liner(3,2) # 定义第二个线性层
def forward(self, x):
# 定义模型的计算
y1 = nn.functional.tanh(self.L1(x))
y = self.L2(y1)
return y
# ------训练数据---------------
X = torch.tensor([[2.5, 1.3, 6.2, 1.3, 5.4, 6 ,4.3, 8.2]
,[-1.2,2.5,3.6,4,3.4,2.3,7.2,3.9]]).T # 输入数据
y = torch.tensor([0,0,1,0,1,1,1,1]) # 样本的标签
# -----模型训练----------------
model = Model() # 初始化模型
lossFun = torch.nn.CrossEntropyLoss() # 损失函数
optimizer = torch.optim.SGD(model.parameters(), lr=0.1) # 初始化优化器
for i in range(500):
py = model(X) # 计算模型的输出值
L = lossFun(py, y) # 计算模型损失值
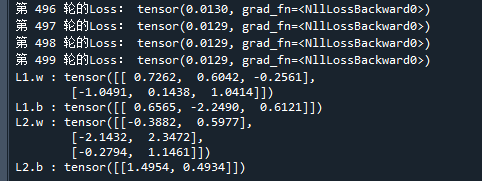
print('第',str(i),'轮的Loss:',L) # 打印当前损失函数值
optimizer.zero_grad() # 更新梯度之前先清空梯度
L.backward() # 用损失函数更新模型系数的梯度
optimizer.step()
# -------打印模型参数-------------------
param_dict = model.state_dict() # 从模型中提取出模型参数
for key in param_dict: # 历遍所有参数名称
print(key,':',param_dict[key].data) # 打印参数名称和数据运行结果如下:
pytorch带模块的模型-代码解说
从上述代码可以看到,我们在模型中把线性层作为一个独立模块,
因为模型的线性层是通用的,独立将它定义为一个模块,这样在模型中就可以重复调用
为什么不能定义为一个函数,而一定要定义为一个模块?
因为线性层里是带参数的,我们必须告诉模型哪些是参数,所以要通过模块的形式来定义
在上述代码中,我们将线性层定义为名为Liner的模块,并在model中调用
而model模块会自动把引用到的Liner模块的参数收集起来,这是Module类的特性
可以看到,打印出来的参数会显示为L1.w的形式,也就是以"子模块名称+参数名称"的形式来命名
本节展示如何使用pytorch提供的模块来构建模型
pytorch提供的模块
pytorch已经提供了许多基础模块,所以在实际使用中,更多时候直接调用就可以了
pytorch提供的模块最常用的可以分为三类:
1. 常用的深度学习层模块:例如卷积层、池化层、全连接(线性)层、BN层等等
2. 激活函数模块:例如ReLu、LeakyReLU、tanh等等
3. 其它:例如Flatten等等
往往我们只需要先在Init初始化这些模块,然后在forward中进行调用就可以了
使用pytorch提供的线性层实现一个三层BP神经网络
下面使用pytorch提供的线性层实现一个三层BP神经网络
具体示例代码如下:
from torch import nn
# -----------定义模型-----------
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.L1 = nn.Linear(2,3) # 定义第一个线性层
self.L2 = nn.Linear(3,2) # 定义第二个线性层
def forward(self, x):
# 定义模型的计算
y1 = nn.functional.tanh(self.L1(x))
y = self.L2(y1)
return y
# -------打印模型参数-------------------
model = Model() # 初始化模型
param_dict = model.state_dict() # 从模型中提取出模型参数
for key in param_dict: # 历遍所有参数名称
print(key,':',param_dict[key].data) # 打印参数名称和数据运行结果如下:
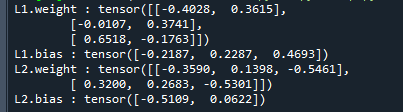
可以看到,只需要在模型中引用pytorch提供的Linear模块,模型中自然就会有Linear模块的权重、阈值等参数
好了,以上就是如何在pytorch中利用模块来构建模型的方法了~
End
 评论
评论