本站原创文章,转载请说明来自《老饼讲解-深度学习》www.bbbdata.com
在pytorch构建了一个模型之后,可以使用pytorch提供的相关方法对模型参数进行初始化与训练
本文讲解在pytorch中如何对构建好的模型进行训练,并展示一个训练的具体代码示例
通过本文,可以初步了解如何对pytorch的模型进行训练,并通过示例了解相关的流程和内容
本节简单讲述在pytorch中是如何训练一个模型的
pytorch是如何训练一个模型的
pytorch面向的是深度学习中的模型,深度学习中的模型往往并非固定结构,而是灵活的"层前馈"结构
所以,pytorch的模型构建、训练往往与传统机器学习的不同,pytorch训练一个模型的流程大概如下:
👉1. 模型的构建
通过继承一个Module类来完成模型的构建,即模型被定义为一个Module类
👉2. 参数初始化
对构建的模型Module类中所定义的模型参数进行初始化
👉3. 模型的训练
对训练样本进行逐批训练,每批样本都调用优化器来完成模型参数的更新,直到满足训练退出条件
总的来说,pytorch是提供了一个更加自由的形式来允许用户定义模型的结构
然后再提供相关的优化器来协助模型的训练,以此达到模型训练既可以个性化又不会太麻烦
本节展示如何使用pytorch来构建一个BP神经网络,并使用优化器进行训练
pytorch训练一个三层BP神经网络
三层BP神经网络是一种经典的神经网络,可用于拟合任意曲线
下面我们展示使用pytorch的模型训练流程来建立一个三层的BP神经网络,并用其拟合sin函数
具体代码示例如下:
import torch
from torch import nn
import matplotlib.pyplot as plt
torch.manual_seed(99)
# ------训练数据----------------
x = torch.linspace(-5,5,20).view(20,1) # 在[-5,5]之间生成20个数作为x
y = torch.sin(x) # 模型的输出值y
# ------构建神经网络模型----------------
class BPModle(nn.Module):
def __init__(self):
super().__init__()
self.nn = nn.Sequential(
nn.Linear(1, 5),
nn.Tanh(),
nn.Linear(5, 1)
)
def forward(self, x):
y = self.nn(x)
return y
model = BPModle()
# ---------------模型训练--------------------
optimizer = torch.optim.SGD(model.parameters(), lr=0.1,momentum=0.9) # 初始化优化器
for i in range(1000):
optimizer.zero_grad() # 将优化器里的参数梯度清空
py = model(x) # 模型的预测值
loss = torch.nn.functional.mse_loss(py, y) # 均方差损失函数
loss.backward() # 更新参数的梯度
print(loss) # 打印当前损失函数值
optimizer.step() # 更新参数
py = model(x) # 模型预测结果
#-----------打印结果--------------------
# 打印训练误差
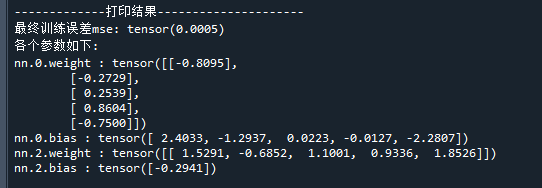
print('\n-------------打印结果---------------------')
print('最终训练误差mse:',torch.mean((py-y)**2).data) # 打印训练误差(均方差)
# 打印模型参数
print('各个参数如下:')
param_dict = model.state_dict() # 提取模型参数
for key in param_dict: # 逐个打印参数
print(key,':',param_dict[key]) # 打印当前参数
# 绘制拟合曲线
t = torch.linspace(-5,5,100).view(100,1) # 用于绘制拟合曲线的x
pt = model(t) # 用于绘制拟合曲线的y
plt.scatter(x, y, c='red', marker='o',label='train data') # 画出训练数据点
plt.plot(t.detach().numpy(), pt.detach().numpy(),label='test data') # 画出拟合曲线
plt.legend() # 显示图例
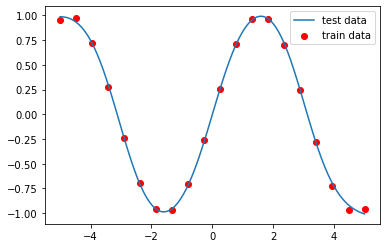
运行结果如下:
模型的训练误差与模型参数如下:
模型对训练样本数据的拟合结果如下
可以看到,训练的模型已经较好的拟合训练样本数据点
好了,以上就是pytorch对模型训练的过程以及例子展示了~
End
 评论
评论