本站原创文章,转载请说明来自《老饼讲解-机器学习》www.bbbdata.com
要实现岭回归模型,可以通过sklearn中的linear_model.Ridge函数来实现
本文展示一个使用sklearn实现岭回归模型的Demo代码,用于参考
通过本文可以掌握如何调用sklearn来实现岭回归模型,以及sklearn实现岭回归的效果
本节展示如何用sklearn实现岭回归模型的求解
问题
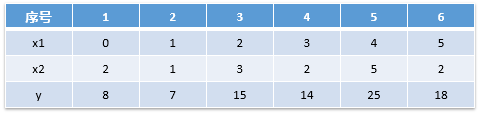
现有数据以下
需要我们建立岭模型,用变量 x1,x2 预测y
✍️备注
以上数据的实际关系为:
建完模可以回头看看建模的结果与这个是否一致
用sklearn包求解岭回归模型
用python的sklearn实现岭回归模型,只需调用linear_model.Ridge()函数即可
具体实现代码如下:
"""
本代码展示一个简单的sklearn实现岭回归的Demo代码
本代码来自《老饼讲解-机器学习》www.bbbdata.com
"""
from sklearn import linear_model
import numpy as np
#输入数据
x = np.array([[0, 2], [1, 1], [2,3],[3,2],[4,5],[5,2]])
y = np.array([8,7,15,14,25,18])
#调用sklearn的线性模型包,训练数据
ridge = linear_model.Ridge(alpha=1,fit_intercept=True) # 模型实例化
ridge.fit(x,y) # 模型训练
#输出模型系数和阈值
print("当前alpha:"+str(ridge.alpha))
print("模型参数:"+str(ridge.coef_))
print("模型阈值:"+str(ridge.intercept_))代码运行结果如下:

可以看到,模型的权重比真实关系的2,3略小,这是因为岭回归中加入了系数的惩罚
好了,以上就是利用sklearn实现一个岭回归模型的DEMO代码了~
End
 评论
评论