本站原创文章,转载请说明来自《老饼讲解-机器学习》www.bbbdata.com
决策树分箱是一种有监督分箱算法,它借助决策树模型对连续变量进行分箱
本文讲解决策树分箱用于连续变量的分箱方法、算法流程以及相关参数,并展示具体的代码实现
通过本文,可以快速了解什么是决策树分箱算法,以及如何使用决策树分箱对来对连续变量进行分箱
本节讲解什么是决策树分箱,以及展示一个决策树分箱例子
什么是决策树分箱
决策树分箱是对连续变量进行变量分箱的一种方法,它属于有监督分箱,即需要有y值
由于决策树分箱要使用决策树模型,如果不熟悉决策树可以参考文章《决策树与CART决策树》
简单来说,决策树分箱就是利用决策树模型进行分箱
它将需要分箱的单个变量与y进行CART决策树建模,将最终的树分割结果作为分箱结果
如下,使用x、y构建决策树,叶子节点就是分箱的结果

最后得到三个分箱:【<=5.45 】、(5.45,6.15】、【>6.15】
决策树分箱-实例讲解
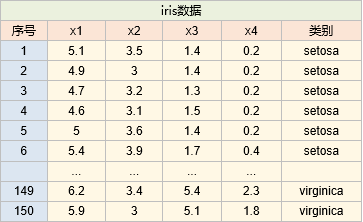
以下是iris数据:
要对x1进行分箱,只需要将x1与类别建立决策树,如下
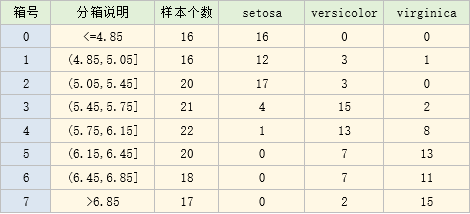
可以看到,只用x1预测类别时,x1的切割点为 [ 5.45,4.85,6.15,5.05,5.75,6.85,6.45]
整理后就得到以下分箱结果:
本节展示决策树分箱的算法流程
决策树分箱流程
决策树分箱的算法流程如下:
1. 将要分箱的x和对应的y,放到决策树中
2. 根据目标分箱个数,调整相关的决策树参数
3. 训练决策树
4. 提取决策树对x的分割点作为分箱结果
备注:最终决策树的每个叶子节点,就是一个分箱
决策树分箱的关键参数
由于在决策树分箱中,最终决策树的每个叶子节点,就是一个分箱
因此,需要通过调整参数来获得想要的分箱个数
在sklearn中,影响分箱个数(叶子节点)的参数有:
min_samples_leaf :叶子节点最小样本数
min_samples_split :节点分枝最小样本个数
max_depth :树分枝的最大深度
min_weight_fraction_leaf :叶子节点最小权重和
min_impurity_decrease :节点分枝最小纯度增长量
max_leaf_nodes :最大叶子节点数
ccp_alpha :CCP剪枝系数
备注:更多关于决策树参数的内容,可以参考《sklearn决策树参数详解》
决策树分箱-代码实现
下面用python实现决策树分箱,它只适用于连续变量
具体代码实现如下:
# -*- coding: utf-8 -*-
"""
决策树分箱
本代码由《老饼讲解-机器学习》www.bbbdata.com编写
"""
from sklearn.datasets import load_iris
from sklearn import tree
import pandas as pd
import numpy as np
# 将类别转为类别矩阵(one-hot格式)
def class2Cmat(y):
c_name = list(np.unique(y)) # 类别名称
c_num = len(c_name) # 类别个数
cMat = np.zeros([len(y),c_num]) # 初始化类别矩阵
for i in range(c_num):
cMat[y==c_name[i],i] = 1 # 将样本对应的类别标为1
c_name = [str(i) for i in c_name] # 类别名称统一转为字符串类型
return cMat,c_name # 返回one-hot类别矩阵和类别名称
# 将切割点转换成分箱说明
def getBinDesc(bin_cut):
bin_first = ['<='+str(bin_cut[0])] # 第一个分箱
bin_last = ['>'+str(bin_cut[-1])] # 最后一个分箱
bin_desc = ['('+str(bin_cut[i])+','+str(bin_cut[i+1])+']'
for i in range(len(bin_cut)-1)] # 中间的分箱说明
bin_desc = bin_first+bin_desc+bin_last # 拼接首尾分箱说明
return bin_desc
# 计算分箱详情
def statBinNum(x,y,bin_cut):
bin_desc = getBinDesc(bin_cut) # 获取分箱说明
c_mat,c_name = class2Cmat(y) # 将类别转为one-hot类别矩阵
df = pd.DataFrame(c_mat,columns=c_name,dtype=int) # 将类别矩阵转为dataFrame
df['cn'] = 1 # 预设一列1,方向后面统计
df['grp'] = 0 # 初始化分组序号
df['grp_desc'] = '' # 初始化分箱说明
# 计算各个样本的分组序号与分箱说明
df.loc[x<=bin_cut[0],'grp']=0 # 第0组样本的序号
df.loc[x<=bin_cut[0],'grp_desc'] =bin_desc[0] # 第0组样本的分箱说明
for i in range(len(bin_cut)-1): # 逐区间计算分箱序号与分箱说明
df.loc[(x>bin_cut[i])&(x<=bin_cut[i+1]),'grp'] = i+1
df.loc[(x>bin_cut[i])&(x<=bin_cut[i+1]),'grp_desc']= bin_desc[i+1]
df.loc[x>bin_cut[-1],'grp']=len(bin_cut) # 最后一组样本的序号
df.loc[x>bin_cut[-1],'grp_desc']=bin_desc[-1] # 最后一组样本的分箱说明
# 按组号聚合,统计出每组的总样本个数和各类别的样本个数
col_dict = {'grp':'max','grp_desc':'max','cn':'sum'} # 按组号聚合
col_dict.update({col:'sum' for col in c_name}) #
df = df.groupby('grp').agg(col_dict).reset_index(drop=True) #
return df # 返器分箱结果
#-----以上部分只用于统计分箱结果详情,与决策树分箱算法无关--------
# -----决策树分箱主函数----------
def treeMerge(x,y,min_samples=10):
clf = tree.DecisionTreeClassifier(min_samples_leaf=min_samples) # sk-learn的决策树模型
clf = clf.fit(pd.DataFrame(x), y) # 用数据训练树模型构建()
bin_cut = clf.tree_.threshold[clf.tree_.children_left>0] # 提取切割点
bin_cut.sort() # 切割点进行排序
bin_desc = getBinDesc(bin_cut) # 生成分箱说明
return bin_cut,bin_desc
#----------使用Demo--------------
# 加载数据
iris = load_iris() # 加载iris数据
x = iris.data[:,0] # 取第0个变量作为分箱变量
y = iris.target # 类别标签
bin_cut,bin_desc = treeMerge(x,y,min_samples=15) # 用决策树进行分箱
bin_stat = statBinNum(x,y,bin_cut) # 计算各个分箱的样本个数
# 打印结果
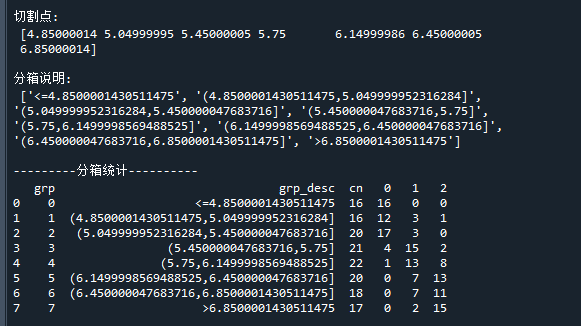
print('切割点:',bin_cut) # 打印切割点
print('分箱说明:',bin_desc) # 打印分箱说明
print('---------分箱统计----------')
print(bin_stat) # 打印分箱统计代码运行结果如下:
从结果中可以看到,它把变量分成了8个组,共7个切割点
好了,以上就是决策树分箱的原理与具体代码实现了~
End
 评论
评论