
本站原创文章,转载请说明来自《老饼讲解-深度学习》www.bbbdata.com
MLP神经网络用于类别预测时,以softmax作为输出层激活函数,并用交叉熵作为损失函数
本文展示一个MLP神经网络用于类别预测的例子,并用pytorch进行实现与训练
通过本文,可以具体了解如何使用MLP神经网络进行类别预测,以及如何使用pytorch实现代码
本节展示一个用MLP解决类别预测的例子,以及具体代码实现
MLP神经网络类别预测-数据说明
本节展示如何使用MLP神经网络来预测类别,为方便理解,不妨采用以下的简单数据:
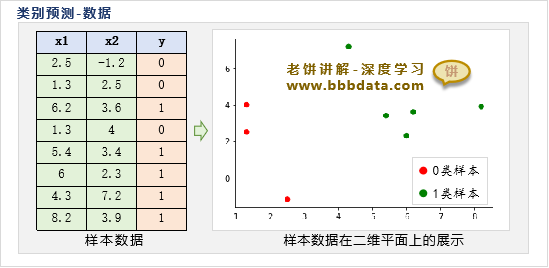
其中,是样本的输入变量,是样本的类别标签
由于样本较为简单,因此本文只采用常规的三层MLP神经网络、4个隐节点进行拟合
整体MLP神经网络模型结构如下:
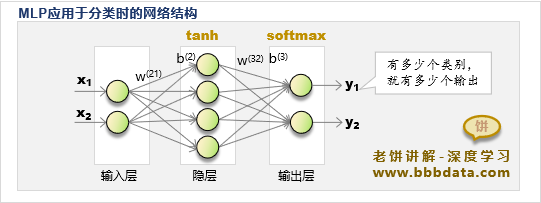
设置好以上的模型之后,将交叉熵作为损失函数,使用SGD对其进行训练即可
pytorch实现MLP神经网络-类别预测
下面使用pytorch来实现上述的MLP神经网络,并使用SGD算法对它进行训练
具体代码如下:
import torch
from torch import nn
import matplotlib.pyplot as plt
torch.manual_seed(99) # 设定随机种子,使得每次运行结果一样
# 定义神经网络的结构
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
self.stack=nn.Sequential(
nn.Linear(2, 4), # 2输入,4输出
nn.Tanh(), # 激活函数用Tanh
nn.Linear(4, 2) # 4输入,2输出(2个类别)
)
def forward(self, x):
y = self.stack(x) # 按stack计算模型输出
return y # 输出y
x = torch.tensor([[2.5, 1.3, 6.2, 1.3, 5.4, 6 ,4.3, 8.2]
,[-1.2,2.5,3.6,4,3.4,2.3,7.2,3.9]]).T # 样本的输入数据
y = torch.tensor([1,1,0,1,0,0,0,0]) # 样本的标签
model = MLP() # 初始化模型
lossFun = torch.nn.CrossEntropyLoss() # 定义损失函数为交叉熵损失函数
optimizer = torch.optim.SGD(model.parameters(), lr=0.01,momentum =0.9) # 初始化优化器
for epoch in range(5000):
optimizer.zero_grad() # 将优化器里的参数梯度清空
py = model(x) # 计算模型的预测值
loss = lossFun(py, y) # 计算损失函数值
loss.backward() # 更新参数的梯度
optimizer.step() # 更新参数
# ----计算错误率----
p_labels = torch.argmax(py,dim=1) # 模型的预测类别
err_rate = (p_labels!=y).sum()/p_labels.numel() # 错误率
print('错误率:' ,(err_rate).numpy()*100,'%') # 打印错误率
if(err_rate<=0.01): # 检查退出条件
break
# -------打印模型训练结果----------
print('----模型训练结果---') # 打印标题
print('错误率:' ,(err_rate).numpy()*100,'%') # 打印错误率
# 绘制预测结果
colors = ['red','g'] # 定义0类的颜色为red,1类样本的颜色为green
labels_color = [ colors[i] for i in y] # 各个样本真实对应的颜色
p_labels_color = [ colors[i] for i in p_labels] # 各个样本预测对应的颜色
plt.scatter(x[:,0], x[:,1],c=labels_color,s=20) # 绘制真实样本
plt.scatter(x[:,0], x[:,1],marker='o',c='none',edgecolors=p_labels_color,s=80) # 绘制预测样本
plt.legend(['true label','predict label']) # 显示图例
plt.show() # 显示画布运行结果如下:

实心点的颜色是样本的真实类别,圆圈的颜色是样本的预测类别
可以看到,模型对所有样本的类别预测都是准确的
备注:在代码中,模型的输出层没有设置softmax函数
因为torch.nn.CrossEntropyLoss实际就是CE(softmax)
好了,以上就是在pytorch上实现MLP神经网络类别预测的代码例子了~
End
 评论
评论