
本站原创文章,转载请说明来自《老饼讲解-深度学习》www.bbbdata.com
在pytorch训练模型前,往往需要先对模型进行初始化,这样可以更有利于模型的训练
本文先讲解如何提取出模型的参数对象,再展示如何对模型的参数进行初始化
通过本文,可以了解在pytorch中如何对模型的参数进行初始化,以及常见的一些初始化方法
本节讲解在pytorch中如何获取、查看模型的参数
如何获取pytorch模型的参数
如果我们只需要查看模型的参数,通过model.state_dict()就能获取模型的全部参数
此外,也可以通过model.named_parameters()或model.parameters()来进行获取参数对象
其中named_parameters返回的参数带名称,而parameters则不带名称,
由于named_parameters和parameters返回的都是迭代器,所以一般需要搭配dict或list函数将它们转换回dict或list对象
具体示例如下:
from torch import nn
# ---------模型定义-----------
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.L1= nn.Linear(1, 3)
def forward(self, x):
y = self.L1(x)
return y
# 打印模型参数
model = Model()
state_dict = model.state_dict()
param_list = list(model.parameters())
param_dict = dict(model.named_parameters())
print('\n-----state_dict获取模型参数----')
print(state_dict)
print('\n-----parameters获取模型参数----')
print(param_list)
print('\n-----named_parameters获取模型参数----')
print(param_dict)运行结果如下:
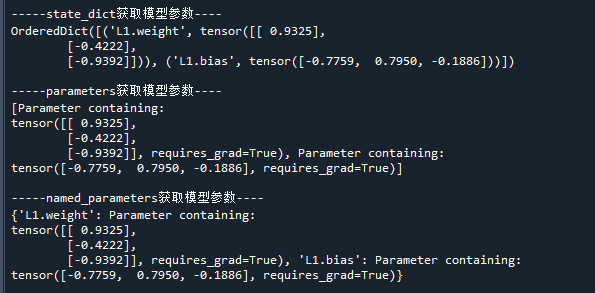
可以看到,state_dict和named_parameters方法获取的参数是带名称的,而parameters方法则不带名称
本节讲解在pytorch中如何对模型参数进行初始化,以及pytorch提供的各种初始化函数
pytorch模型参数初始化
将pytorch模型的参数进行初始化,就是获取每个参数,然后将其修改成合理的初始值
我们可以直接修改参数的初始值,更一般地是通过pytorch提供的各种初始化函数来初始化参数
需要注意的是,如果通过state_dict获取参数,并修改state_dict是不会改变模型参数的
一般通过过parameters或named_parameters来获取参数对象,并对其进行修改
具体示例如下:
from torch import nn
import torch
# ---------模型定义-----------
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.C1 = nn.Conv2d(1,2, kernel_size=3,stride=1,padding=1)
self.F = nn.Flatten()
self.L2 = nn.Linear(2,3)
def forward(self, x):
y = self.F(self.Cov(x))
y = self.L2(y)
return y
# -------模型参数初始化----------------------
def init_param(model):
param_dict = dict(model.named_parameters()) # 获取模型的参数字典
for key in param_dict: # 历遍每个参数,对其初始化
param_name = key.split(".")[-1] # 获取参数的尾缀作为名称
if (param_name=='weight'): # 如果是权重
torch.nn.init.normal_(param_dict[key]) # 则正态分布初始化
elif (param_name=='bias'): # 如果是阈值
torch.nn.init.zeros_(param_dict[key]) # 则初始化为0
# ------展示效果--------------------------
model = Model() # 初始化模型
init_param(model) # 初始化模型参数
print(model.state_dict()) # 打印结果运行结果如下:
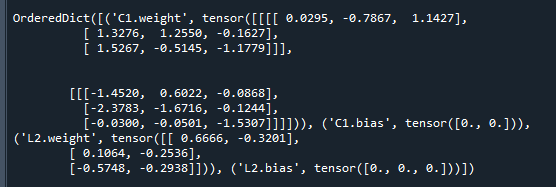
可以看到,权重用正态分布初始化,而阈值则初始化为0
pytorch提供的初始化参数
pytorch提供了各种各样常用的参数初始化函数,例如将参数初始化为常数、正态分布等等
常数初始化
初始化为指定常数 :torch.nn.init.constant_(tensor, val)
初始化全为1的常数:torch.nn.init.ones_(tensor)
初始化全为0的常数:torch.nn.init.zeros_(tensor)
初始化为单位矩阵 :torch.nn.init.eye_(tensor) :
一般的随机概率分布初始化方法
均匀分布:torch.nn.init.uniform_(tensor, a=0.0, b=1.0, generator=None)
正态分布:torch.nn.init.normal_(tensor, mean=0.0, std=1.0, generator=None)
截断正态分布:torch.nn.init.trunc_normal_(tensor, mean=0.0, std=1.0, a=-2.0, b=2.0)
稀疏正态分布初始化:torch.nn.init.sparse_(tensor, sparsity, std=0.01)
Xavier初始化、凯明初始化与正交初始化
Xavier均匀分布:torch.nn.init.xavier_uniform_(tensor, gain=1.0, generator=None)
Xavier正态分布:torch.nn.init.xavier_normal_(tensor, gain=1.0, generator=None)
凯明均匀分布 :torch.nn.init.kaiming_uniform_(tensor, a=0, mode='fan_in', nonlinearity='leaky_relu')
凯明正态分布 :torch.nn.init.kaiming_normal_(tensor, a=0, mode='fan_in', nonlinearity='leaky_relu')
正交初始化 :torch.nn.init.orthogonal_(tensor, gain=1, generator=None)
pytorch对相关初始化API的说明文档: 《pytorch的官方初始化API说明》
好了,以上就是在pytoch中如何对模型的参数进行初始化的方法与示例了~
End
 评论
评论