本站原创文章,转载请说明来自《老饼讲解-深度学习》www.bbbdata.com
RNN循环神经网络(Recurrent Neural Network)是一种拓展自MLP神经网络、专门应用于处理序列数据的模型
本文讲解RNN的网络结构以及运算过程,以及RNN在实际使用中的一些常见结构,并展示一个RNN解决序列预测的代码实现
通过本文,可以快速了解RNN循环神经网络是什么,如何理解RNN的意义,以及如何使用RNN来解决序列预测问题
本节讲解RNN神经网络的结构和计算方法
基础RNN神经网络的结构
RNN循环神经网络(Recurrent Neural Network)是一种拓展自MLP神经网络、专门应用于处理序列数据的模型
RNN神经网络的拓扑图一般以时序形式来展示, 一个包含3个时刻的RNN神经网络的拓扑结构图如下:
可以看到,RNN每个时刻都相当于一个三层的MLP神经网络,只是同时把上一时刻的隐层也作为输入
因此,一个RNN模型共有三个权重和两个阈值:
隐层权重阈值 :隐层权重W、D与隐层阈值B
输出层权重阈值 :输出权重与输出层阈值
基础RNN模型的计算公式
RNN每个时刻先计算当前时刻的隐层与输出,并保留隐层的值作为下一时刻的延迟输入
RNN神经网络在时刻的输出的计算公式如下:
其中:
:隐层的激活函数,一般取为tanh或ReLu函数
:输入层到隐层的权重
:上一时刻的隐层到当前时刻的隐层的权重
:网络隐层的阈值
:隐层到输出层的权重
:隐层到输出层的阈值
按上述公式循环计算,就可以得到每一时刻的输出
由于第一个时刻并没有"上一时刻",所以第一个时刻的延迟输入需要自行初始化,
一般将初始时刻的延迟输入初始化为0,即
本节讲解如何理解RNN循环神经网络,进一步加深对RNN的理解
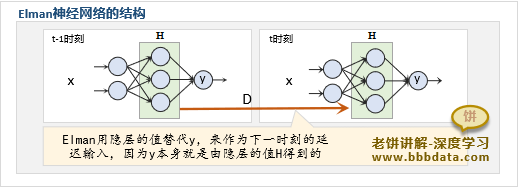
从"延迟输入"理解RNN
对RNN的第一种理解,可以用延迟输入的方式来理解,它是RNN最初诞生时的初衷
Jordan神经网络
这得从Jordan神经网络讲起,由于时间序列的y,除了受当前X的影响,还受上一时刻的y的影响
因此,Jordan将MLP上一时刻的y也作为当前时刻的输入(称为延迟输入),以此解决序列预测问题
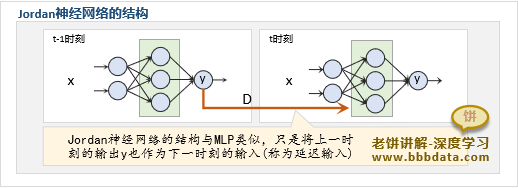
Jordan神经网络的思想很朴素,纯粹就是把上一时刻MLP的输出加入到下一时刻的输入中
Elman对Jordan神经网络的改进
而基础RNN则是Jordan神经网络的改进,由Elman于1990年提出,当时称为Elman神经网络
Elman在Jordan的基础上,将上一时刻的隐层来作为延迟输入,来替代Jordan中的延迟输入y
Elman这样做的理由是,既然y是隐节点H得到的,那何不直接用隐节点H来作延迟输入呢
比起用y来作延迟输入,使用隐层节点H能让下一时刻的延迟输入的信息更加原始,信息更加充分
RNN的原理-总结
因此,RNN的原理其实很简单,它的本质就是一个用于解决序列问题的MLP神经网络
只不过因为当前y依赖于上一时刻的y,所以把上一时刻的y也作为当前时刻的输入
而更进一步地,使用信息更加原始的隐层H来替代y,使得当前时刻的延迟输入信息更加充分
从"隐信息"理解RNN
RNN的第二种理解方式是从信息更新的角度来理解,也是目前较为常见的理解方式
它假设序列y实际由一组隐信息(以隐节点来表示)来生成,然后使用每个时刻的输入来更新隐信息
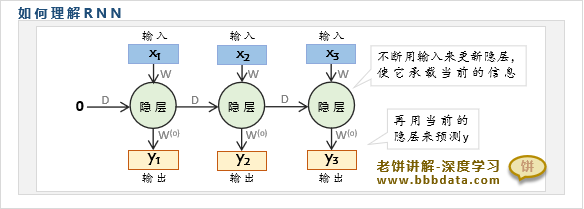
由于每个时刻都用输入来更新隐节点,因此隐节点承载了过去所有时刻的信息,再用隐节点预测
因此,输出就代表隐信息与输出之间的关系
而隐层的计算公式也就代表着隐节点的更新规则
与的权重的意义就可以解释为"最新信息与历史信息相结合时的权重"
可知,在H与y的关系、H的更新规则上,基础RNN都是以最最最简单的形式来设置,所以它是一个再简单不过的模型
这也就注定了后面会有各种RNN的改进模型,例如LSTM,GRU等等,因为基础RNN模型本身留下了充足的改造空间
本节介绍RNN循环神经网络在实际应用时的各种模型结构
RNN的几种基础常见结构
基础RNN模型在实际使用中,衍生了NVN、NV1、1VN三种常见的基础应用结构
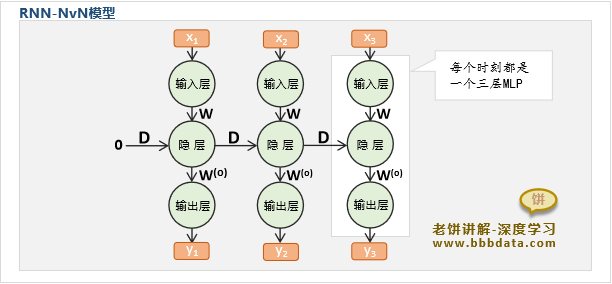
RNN神经网络-NVN结构
基础RNN模型的结构就称为NVN结构,因为它有N个时刻的输入与N个时刻的输出
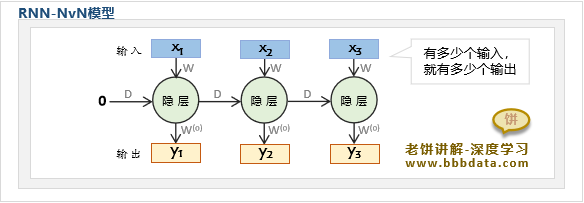
NvN模型在使用中,主要应用于经典的序列预测问题,即每个时刻都有输入,且受上一时刻输出的影响
NVN举例:例如房价预测,当年的房价,除了受楼层、采光、面积、地区等的影响,还受上一年的房价影响
此时,每一时刻都需要输入当前的X,然后输出当前时刻预测的房价y
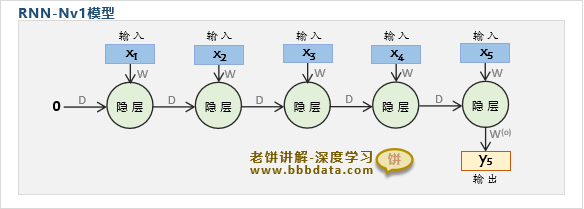
RNN神经网络-Nv1结构
RNN的Nv1模型是NvN的变种, Nv1是指模型的输入序列为任意长度,输出序列长度固定为1
RNN-Nv1模型的结构示图如下:
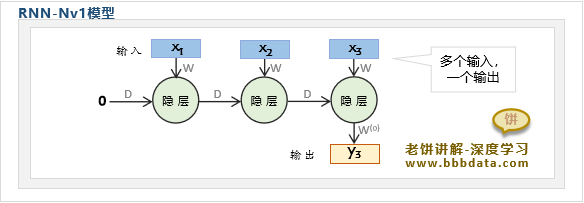
可以看到,NV1其实就是取消了NvN在过程中的输出,只保留最后一个输出结果
NV1举例:判断序列的类别时,就是NV1模型,例如输入一个词语,然后输出词语的情感类别
RNN神经网络-1VN结构
RNN的1vN模型,是指模型的只有首时刻的输入,然后输出时刻长度固定为N
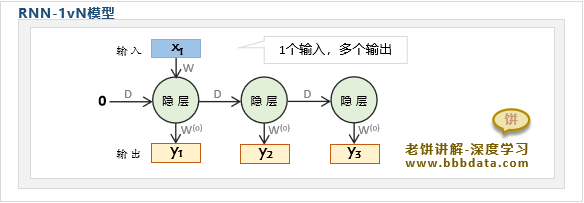
可以看到,RNN的1vN模型则是在NvN的基础上,去掉除首时刻外其它时刻的输入,
也就是它只在第一时刻进行输入,然后每一次迭代就得到一个输出,迭代n次,得到n个输出
举例:输入首时刻的状态,然后预测未来N个时刻的值
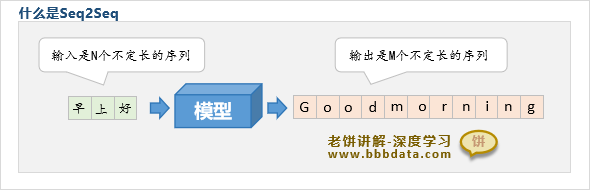
RNN的NVM结构
特别地,当一个模型的输入与输出都是一个不定长的序列时,则称为seq2seq模型,也称为NVM模型
例如中英翻译模型,输入的中文是不定长的,而输出的英文也是不定长的
RNN一般采用Encoder-Decoder结构来解决seq2seq问题,也称为RNN-NVM结构,如下:
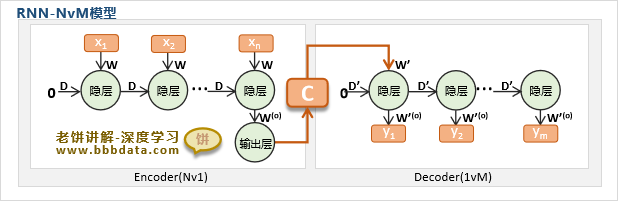
如图所示,Encoder-Decoder的思想就是把输入信息先转换为一组编码信息C,再把C转换为输出信息
RNN-NVM模型只需把Nv1模型作为Encoder,把1vM模型作为Dncoder,就可以解决NvM的seq2seq问题
本节展示如何使用RNN来解决序列预测问题,以及RNN的代码实现
RNN案例-sin函数拟合-问题描述
作为简单的入门,我们以sin函数为例,因为sin函数就是一个时序性非常强的函数,极具代表性
因此,本文以sin函数为例,简单上手与了解如何使用RNN解决序列数据的预测
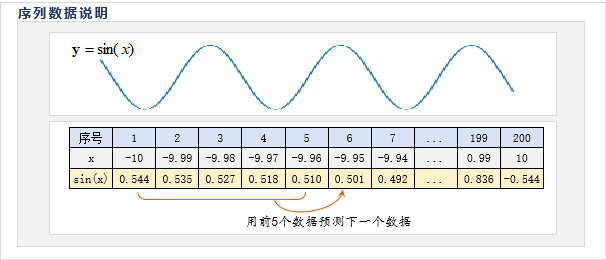
如图所示,以下是一个sin函数的曲线与序列数据,我们希望通过前5个数据预测下一个数据
在本问题中,属于单时刻输出的预测,因此,是一种最简单的场景,我们以此来作为初步上手RNN
RNN模型设计
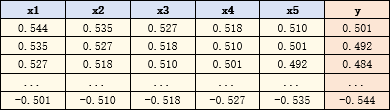
我们将数据处理为以下的形式:
x1-x5是t时刻之前的5个数据,y是本时刻的数据,我们使用x1-x5来预测y
我们设计一个Nv1的RNN模型如下:
它的意义就是,将前5个时刻的X按顺序更新到隐节点,再用承载了所有输入信息(x1-x5)的隐节点来拟合输出y
下面我们使用pytorch来实现上述所设计的模型,以及训练模型
值得注意的是,在计算损失函数时,我们只需考虑最后一个时刻的预测值的损失
具体实现代码如下:
import torch
import random
import torch.nn as nn
import matplotlib.pyplot as plt
# ----------------------数据生成--------------------------
data = torch.sin(torch.arange(-10, 10,0.1)) # 生成sin序列数据
plt.plot(data)
seqLen = 5 # 利用前5个时刻预测下一时刻
sample_n = len(data)-1-seqLen-1 # 样本个数
x = torch.zeros(seqLen,sample_n,1) # 初始化x
y = torch.zeros(1,sample_n,1) # 初始化y
for i in range(sample_n): # 从序列数据中获取x与y
x[:,i,:] = data[i:i+seqLen].unsqueeze(1) # 将前5个数据作为x
y[:,i,:] = data[i+seqLen] # 将下一个数据作为y
valid_sample_n = round(sample_n*0.2) # 抽取20%的样本作为验证样本
idx = range(sample_n) # 生成一个序列,用于抽样
valid_idx = random.sample(idx, valid_sample_n) # 验证数据的序号
train_idx = [i for i in idx if i not in valid_idx] # 训练数据的序号
train_x = x[:,train_idx,:] # 抽取训练数据的x
train_y = y[:,train_idx,:] # 抽取训练数据的y
valid_x = x[:,valid_idx,:] # 抽取验证数据的x
valid_y = y[:,valid_idx,:] # 抽取验证数据的y
#--------------------模型结构----------------------------------
# RNN神经网络的结构
class RnnNet(nn.Module):
def __init__(self,input_size,out_size,hiden_size):
super(RnnNet, self).__init__()
self.rnn = nn.RNN(input_size, hiden_size)
self.fc = nn.Linear(hiden_size, out_size)
def forward(self, x):
h,_ = self.rnn(x) # 计算循环隐层
h = h[-1,:,:].unsqueeze(0) # 只需要最后一个时刻的隐节点
y = self.fc(h) # 计算输出
return y,h
#--------------------模型训练-----------------------------------
# 模型设置
goal = 0.0001 # 训练目标
epochs = 20000 # 训练频数
model = RnnNet(1,1,10) # 初始化模型,模型为1输入,1输出,10个隐节点
lossFun = torch.nn.MSELoss() # 定义损失函数为MSE损失函数
optimizer = torch.optim.SGD(model.parameters(), lr=0.01) # 初始化优化器
# 模型训练
for epoch in range(epochs):
optimizer.zero_grad() # 将优化器里的参数梯度清空
train_py,_ = model(train_x) # 计算模型的预测值
train_loss = lossFun(train_py, train_y) # 计算损失函数值
valid_py,_ = model(valid_x) # 计算模型的预测值
valid_loss = lossFun(valid_py, valid_y) # 计算损失函数值
if(epoch%1000==0):
print('------当前epoch:',str(epoch),'----------') # 打印当前步数
print('train_loss:',train_loss.data) # 打印训练损失值
print('valid_loss:',valid_loss.data) # 打印验证损失值
if(train_loss<goal): # 如果训练已经达到目标
break # 则退出训练
train_loss.backward() # 更新参数的梯度
optimizer.step() # 更新参数
# ------------------展示结果--------------------------------------
py,_ = model(x) # 模型预测
loss= lossFun(py, y).data # 打印损失函数
print('整体损失值:',loss)
plt.figure() # 初始化画布
plt.plot( y[0,:,0], color='r', linestyle='-.',label='true_y') # 绘制真实曲线
plt.plot( py[0,:,0].detach(), color='b', linestyle='-.',label='predict_y') # 绘制预测曲线
plt.legend(loc=1,framealpha=1) # 展示图例
plt.show() # 展示图像运行结果如下:
------当前epoch: 0 ----------
train_loss: tensor(0.9424)
valid_loss: tensor(0.8353)
------当前epoch: 1000 ----------
....
------当前epoch: 19000 ----------
train_loss: tensor(0.0002)
valid_loss: tensor(0.0002)
-----------------------------------------
整体损失值: tensor(0.0002)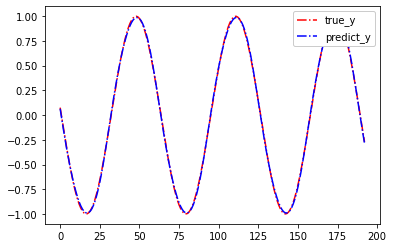
可以看到,模型整体的损失值(MSE)已经极小,所预测的y与真实y已经几乎完全一样
好了,以上就是RNN循环神经网络的模型结构与代码实现了~
End
 评论
评论