本站原创文章,转载请说明来自《老饼讲解-机器学习》www.bbbdata.com
信息量是机器学习中常用的概念,例如决策树、逻辑回归等模型就是基于信息量而提出的
本文讲解香农信息量的定义、计算公式和推导过程,以及信息量在机器学习中的意义
通过本文,可以知道信息量是什么,如何计算以及在机器学习中应该如何理解信息量
本节讲解香农信息量是什么及香农信息量是如何定义出来的
信息量的定义与计算公式
信息量是信息的量化指标,用于衡量信息的大小,最常用的是香农信息量
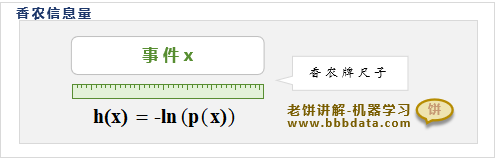
香农信息量的定义与计算公式如下:
其中,:事件发生的概率
:事件所包含的香农信息量
可以看到,香农信息量与事件的概率成反比,概率越小的事件,信息量就越大
例如有人告诉我"明天太阳会升起来",我就没能从中获得什么信息量,这事概率太大了
✍️笔者小故事:关于信息量的非客观性
笔者刚开始接触信息量时,曾经疑问"为什么这件事的信息量是 -ln(p)?”
后来才明白,信息量并不是一种客观存在的"量" ,它只是一种人为的定义
所以, 只是用香农定制的这把"尺子"来度量事件的信息大小时的值
它既不是客观存在的量,也不是"信息量"的唯一值,而仅仅只是"香农信息量"
机器学习与信息量
信息量主要用于衡量一个事件中所包含的信息的多少
因此,在知道一个事件后,如果获得的信息量越多,则代表事前对它越一无所知
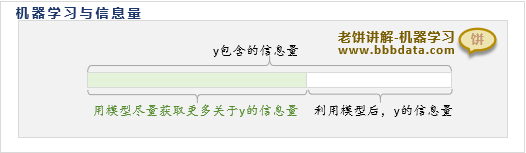
机器学习中,建立模型的目的就是希望事前用模型获得更多关于样本y值的信息量
事前通过模型获取越多y值的信息量,事后知道y真实值时所获得的信息量就越少
也可以把模型带给我们关于y的信息量,看作对y的了解程度
把事后知道y的真实值所获得的信息量,看作"y的震惊程度"
当模型预测结果与真实值一致时,真相就与我们预期一致,就没什么好惊讶的
本节讲解香农信息量是如何定义出来的,并从中了解它的特性
香农是如何定义信息量的
香农信息量是香农定义出来的,他对信息的量化主要有三步:
👉1. 确定信息是具有可量化性的
👉2. 探究信息量化公式应该满足的特性
👉3. 根据量化值的特性,反推出信息量的定义公式
信息的可量化性
信息是一个抽象的概念,但我们隐约可以感觉,信息是有大小之分的
例如“小明爱吃榴莲”显然比“小明爱吃米饭”这件事的信息量更多
进一步仔细探究后,会发现信息量的大小,与事件发生的概率负相关
即知道一个越小概率发生的事件,从中所能获取到的信息量就会越大
既然信息有了大小之分,于是香农(Shannon)决定正式把它量化
信息量需要满足的特性
既然要把信息量化,那么,信息量应该满足什么特性呢?
香农总结后,认为需要满足以下三个特性:
1. 单调性
从日常直觉总觉来说,概率越小的事情,信息量应该越大
也就是说,信息量应该与事件发生的概率负单调
2. 非负性
信息量的最小值应该为0,不能是负数
3. 累加性
两个独立事件各自的信息量之和,
需要与这两个独立事件构成的整体事件的信息量相等
例如,"小明爱吃米饭”和“小明是小学生”的信息量之和
应该等于“小明是个爱吃米饭的小学生”
香农对信息的量化过程
不妨用h来表示信息量,由它与概率的负单调性
可以知道,h应该有以下形式:
其中, F是负单调函数
又由于累加性,独立事件的总信息等于独立事件的信息和
可知,h应该满足:
即负单调函数应满足:
而刚好满足这条件,于是香农用作为
则,信息量定义为:
好了,信息量的概念与意义就写到这了~
End
 评论
评论