本站原创文章,转载请说明来自《老饼讲解-机器学习》www.bbbdata.com
KL散度是机器学习中常用的指标之一,它常用于衡量两个分布之间的差异
本文讲解KL散度的公式,KL散度的用途,以及KL的原理和它是如何被定义出来的
通过本文可以快速了解KL散度是什么,用什么用,以及KL散度的背景意义和推导过程
本节讲解KL散度公式和计算例子,并介绍KL散度的相关应用场景
KL散度是什么
KL散度公式
KL散度(Kullback-Leibler divergence)也称为KL距离,它用于计算两个分布的距离(差异)
分布 Q(X)与 P(X) 的KL散度计算公式为:
其中,P一般称为真实分布,Q则指认知分布,KL用于度量Q与P的距离
注意:KL虽然有距离之称,但它是不对称的,即Q与P的KL散度不等于P与Q的KL散度
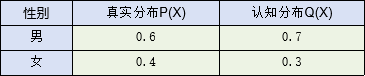
✍️ KL散度计算例子
真实分布P和认知分布Q如下所示,现计算Q与P的距离
根据KL散度公式,可以计算得到:
KL散度的用途
KL散度广泛应用于机器学习,与分布相关的都能看到它的身影,下面列兴趣一二
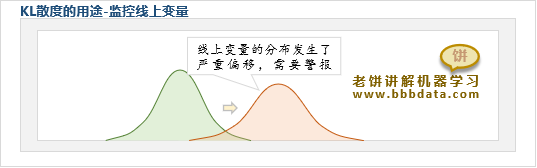
KL散度应用场景一:监控变量分布
由于模型一般是基于历史样本训练的,所以随着时间推移,可能不适用于线上数据
此时,可以使用KL散度来监控线上变量的分布是否与建模时的训练数据的分布一致
当KL散度大于一定阈值时,就自动发警报,方便建模人员进行分析与采取相关措施
KL散度应用场景二:作为损失函数的正则项
在训练模型的时候,可以用KL散度作为正则项,强制使模型的预测值趋向目标分布
例如著名的VAE自动编码器模型中,就引入KL散度,使其编码器的输出偏向正态分布
使用KL散度作为正则项,可以抵抗过拟合,它可以使模型预测值的分布更加合理化
本节讲解KL散度的原理与推导,从而更进一步理解KL的意义
KL散度的原理与意义
KL是基于信息熵与交叉熵的基础上进行定义的,
下面先简单回顾信息熵与交叉熵的,再进而说明KL散度的原理
变量的信息熵
假设变量的分布为, 即X取值为的概率为
当我们了解X的分布概率P时,在知道真相()时,所获得的信息量就为
由于X的所有可能取值为,所以知道X真实取值时获得的信息量期望为:
上式就称为变量的熵,它代表知道一个以P分布的变量的真实值时所获得的期望信息量
变量的交叉熵
当不知道X的真实分布 ,而是认为X的分布为 时
此时由于认为X取值为的概率为,则在知道时获得的信息量就为
由于X的所有可能取值为,所以知道X真实取值时获得的信息量期望为:
上式就称为变量的交叉熵
它代表以分布Q去认识一个分布P的变量时,在知道X的真实值时所获得的期望信息量
KL散度的意义
从信息熵与交叉熵可知,信息熵是我们掌握X的真实分布时获得的信息量期望
而交叉熵是我们不知道X的真实分布时获得的信息量期望
没有掌握真实分布时获得的信息量,肯定比掌握了真实分布时获得的信息量更加大
即,当认知分布Q(x)与真实分布P(x)偏差越大的时候,交叉熵就就比信息熵更加大
因此,我们用两者的差来定义Q(x)与P(x)的差异,称为KL散度:
KL散度直接评估了交叉熵与信息熵的差异,从而间接地评估了P(x)与Q(x)的差异
KL散度大于等于0的证明
KL散度作为两个分布的距离,它是一定不小于0的,下面证明为什么KL散度>=0
证KL散度>=0,即证:
证明过程需要利用不等式:,利用此不等式可轻易证明KL散度不小于0
KL散度不小于0的证明过程如下:
由于:
即
故有:
即
✍️附:的证明
令
令导数为0,则有
可知f(x)在1处取得极值,且易知是极大值,从而有
即
从而得到
好了,以上就是KL散度的介绍以及原理推导了~
End