本站原创文章,转载请说明来自《老饼讲解-深度学习》www.bbbdata.com
softmax函数与交叉熵函数是机器学习中类别预测最常用的两个函数
本文讲解softmax函数与交叉熵函数的具体原理及推导,
通过本文可以了解softmax函数与交叉熵函数是怎么来的,它们的背景意义是什么
本节简单介绍softmax函数与交叉熵损失函数
softmax函数与交叉熵函数
softmax与交叉熵损失函数是两把利器,可以把一切数值预测模型转化为类别预测的模型
其中,softmax负责把模型的预测数值转换为概率,而交叉熵损失函数则引导模型各个参数的求解
softmax与交叉熵损失函数几乎成为了最常见的搭配,而它们的原理都同样来源于信息学
本文详细解释softmax与交叉熵两者到底是怎么来的,它们背后的意义的原理各是什么
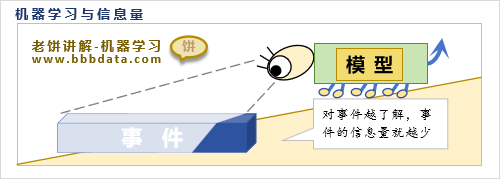
信息量回顾
为方便理解softmax与交叉熵损失函数,下面我们先回顾简单信息量是什么
如果发生事件A的概率为p,那么事件A的信息量根据信息学的定义就为-ln(p)
例如一般明天下雨的概率为0.3,现在我告诉你,明天会下雨,这件事的信息量就为-ln(0.3)
在机器学习中,我们希望信息量越低越好,说明这件事尽在我们掌握之中,惊讶不到我们
可以将信息量理解为事件的“震惊程度”,信息量越大(事件发生的概率越低),越让人惊讶
本节讲解softmax函数的原理,通过本节可以了解softmax函数是怎么来的
softmax的原理
在深度学习中经常用到softmax函数,将数值转换为概率,
那么,softmax函数是怎么来的?它的背景意义是什么?为什么能把数值转换为概率?
softmax的整体原理源自于信息学,它把看作模型从X中得知样本属于类别i的信息量,
再根据信息量与概率的关系,把转换为概率, 下面进行简单推导与讲述
softmax的公式如下:
,即
假设样本属于各个类别的总信息量都为b,则事后得知样本类别时所获得的信息量应当扣除
即得知样本属于第i个类别时所获得的信息量为,即如下:
即
进一步消去b,则有:
所以,一个好的模型应能从X中获取更多的样本真正类别的信息量,即真正类别对应的z应更加大
备注:上述推导中把作为已获取信息量,所以不能为非负数,
但事实上softmax中的是可以为负数的,这只需进行一个简单的推广就可以,这里不再拓展
本节讲解交叉熵损失函数的原理,通过本节可以了解交叉熵损失函数是怎么来的
交叉熵损失函数的原理
现有m个样本,假设第i个样本真实标签为第k类,而我们认为它属于第k类的概率为,
在这个认知的基础上,当我们知道样本的真实标签时,
每个样本带给我们的平均震惊程度,也就是信息量期望(熵)为
其中,为第i个样本属于真实类别的预测概率
这就是交叉熵损失函数,又由于我们的预测结果一般是如下的概率矩阵
由于类别的数量一般远小于样本数据,计算时一般按类别进行历遍,
所以我们一般将交叉熵损失函数写成如下形式
其中,为第i个样本属于第k类的概率,k是样本的真实类别
好了,以上就是softmax函数与交叉熵函数的原理了~
End