本站原创文章,转载请说明来自《老饼讲解-深度学习》www.bbbdata.com
ResNet(ResidualNetwork,残差神经网络)是2015年提出的一种带有残差快捷连接的卷积神经网络
本文讲解ResNet解决网络退化问题的原理,以及ResNet的模型结构,并展示ResNet的代码实现
通过本文,可以快速了解ResNet是什么,解决了什么问题,以及如何使用ResNet来解决图片类别识别问题
本节介绍什么是ResNet神经网络,以及ResNet模块的意义
什么是ResNet
ResNet是2015年提出的一种卷积神经网络,它的核心是通过残差快捷连接来解决网络退化问题
ResNet神经网络原文:《Deep Residual Learning for Image Recognition》
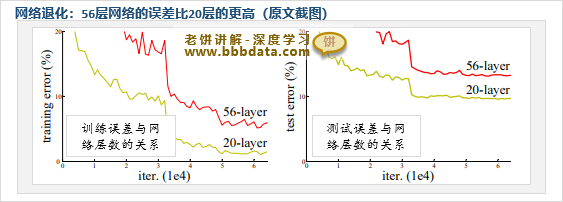
网络退化是指神经网络层数加深到一定程度后,继续加深网络不但不会降低误差,反而使网络效果更差
ResNet最大的贡献就是解决了网络退化问题, 如下所示,56层网络的误差比20层的误差还要高
网络退化使得深度学习的层数不能太深,在ResNet出现之前,一般最多也只有100层
而ResNet引入ResNet模块来解决网络退化问题,使用ResNet模块,即使模型深度达到1000层也没问题
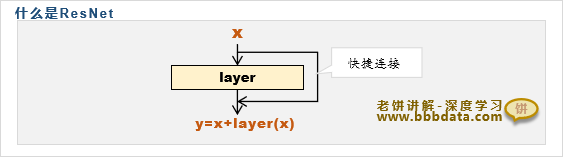
什么是ResNet模块
ResNet模块就是在原来的神经网络层添加一个快捷连接(shortcut),把输入添加到输出上,如下所示
为什么ResNet可以有效地解决网络退化问题呢?可如下理解:
1. 快捷连接减轻了该层神经网络的拟合复杂度,它只拟合增量(残差),从而解决网络退化的问题
2. 这种快捷连接使该层易于成为恒等网络(即输入与输出一致),从而解决网络退化的问题
因为易于成为恒等网络,所以增加层时,即使不能降低误差,也不致于增加误差,所以网络不会退化
什么是ResNet模型
ResNet原文在ImageNet和CIFAR-10数据集上展开了一系列的关于ResNet模块相关的实验与探索
其中,在面向ImageNet数据做相关实验时提出了ResNet-18、34、50、101、152 共5个模型
在面向CIFAR-10数据做相关实验时提出了ResNet-20、32、44、56、110、1202 共6个模型
狭义上,ResNet神经网络就是指以上11个模型,但更广义地,使用了ResNet模块的都可以称为ResNet模型
ResNet模块与快捷连接方式
ResNet模块
ResNet原文提供了普通ResNet模块和Bottleneck-ResNet模块
普通ResNet模块和Bottleneck-ResNet模块如下:
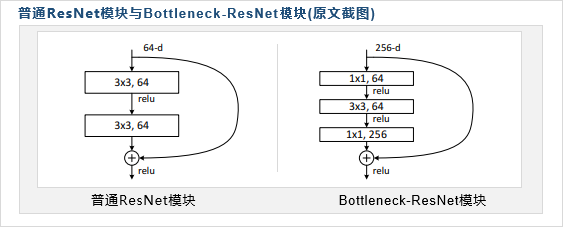
普通ResNet模块就是直接添加了一个快捷连接,使得被快捷连接跨越的层的意义变为拟合残差
Bottleneck-ResNet模块就是在普通ResNet模块首、尾层加入了1×1卷积,用于控制输入输出的降、升维
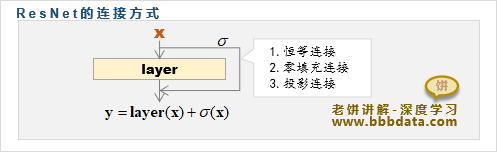
ResNet的快捷连接方式与连接方案
在ResNet模块中,最终的输出由输入与层输出相加得到
为了使与的维度必须相同,一般需要先对进行转换,使得它与的维度对齐
即:
其中是一个简单的、旨在与维度layer(x)对齐的映射
ResNet原文中提供了三种连接方式,如下:
1. 恒等连接
即
恒等连接只有x与layer(x)维度一致时才能使用
2. 零填充连接
即为"用0将x填充到与layer(x)一样的维度"
3.投影连接
即
假设layer(x)有m个通道,x有n个通道,
则投影快捷连接可以理解为将x的n个维度重新线性组合成m个维度
恒等连接与零填充连接都不需要额外的参数,而投影连接则需要引入新的、待训练的参数w
由于整个深度神经网络中可能会有多个ResNet模块,有的x与layer(x)维度一致,而有的维度不一致
ResNet原文共提供了三种连接方案供整个网络选用:
A:升维时用零填充快捷链接,其他为恒等快捷链接
B:升维时用投影快捷链接,其他为恒等快捷链接
C:所有链接都用投影快捷链接
本节介绍ResNet原文中的两组ResNet网络结构
ResNet-20、32、44、56、110、1202网络结构
ResNet原文在面向CIFAR-10数据做相关实验时,提出了 ResNet-20、32、44、56、110、1202共6组模型
模型输入:32×32×3的图片
模型输出:10个类别的概率向量
ResNet-20、32、44、56、110、1202的通用结构如下:
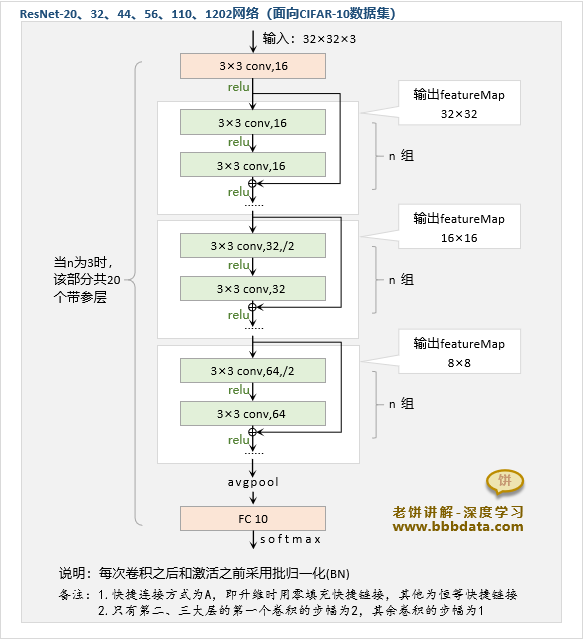
设n设为n ={3,5,7,9,18,200}时,就可分别得到ResNet-20、32、44、56、110、1202模型
值得注意的是,ResNet-1202是一个超深网络,它已经超过了1000层
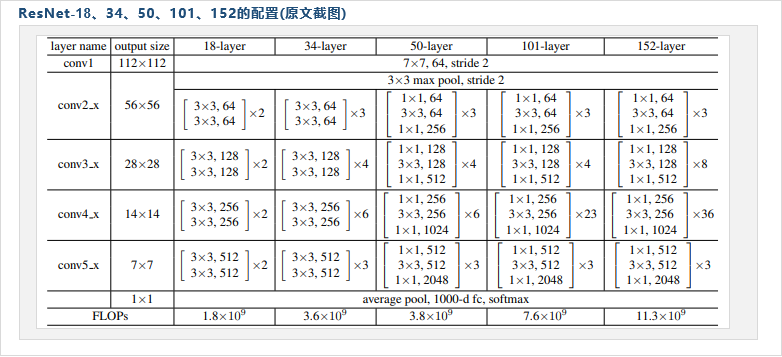
ResNet-18、34、50、101、152网络结构
ResNet原文在面向ImageNet数据做相关实验时,提出了ResNet-18、34、50、101、152共5组模型
ResNet-18、34、101、152都是简单的卷积神经网络上添加上快捷链接
ResNet-18的模型结构如下:
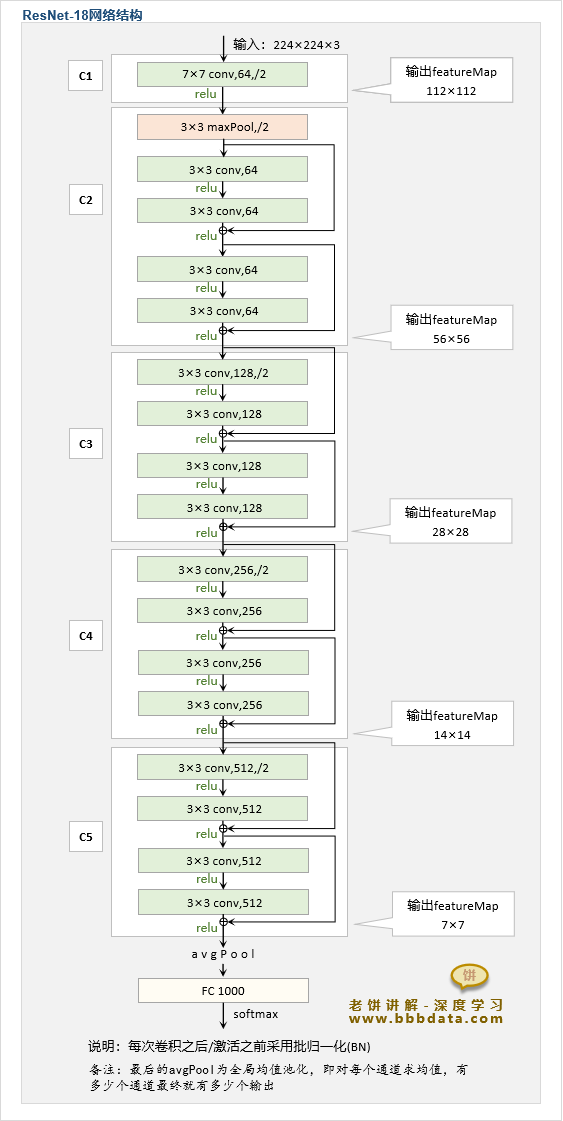
可以看到,ResNet-18的架构主要借鉴自VGG,例如5大卷积层、使用多个3×3卷积等等
ResNet-18中,C1是一个大卷积,快速将输入图片信息融合,而C2-C5卷积层都由多个ResNet模块堆叠而成
值得注意的是,C2是通过maxpool来减小FeatureMap的Size,而C3、C4、C5则令首个卷积步幅为2来减小FeatureMap
其中,快捷连接方案使用B方法,即“升维时用投影快捷链接,其他为恒等快捷链接”
ResNet-18、34、50、101、152模型
对于其它模型(ResNet-34、50、101、152)则是在18层的形式上,按以下表格修改配置得到:
可以看到,ResNet-50、101、152使用了Bottleneck-ResNet模块,
这主要是Bottleneck-ResNet模块的性价比更优,在构建深层ResNet中,改用Bottleneck-ResNet模块的优势会更明显
本节展示如何实现一个ResNet用于图片类别识别
pytorch中的ResNet模型
pytorch中提供了ResNet模型,我们可以将pytorch中的ResNet模型结构打印出来
以ResNet18为例,具体代码如下:
import torchvision
model = torchvision.models.resnet18() # 初始化模型
print('\n resnet18的模块:\n',dict(model.named_children()) ) # 打印模型的模块运行结果如下:
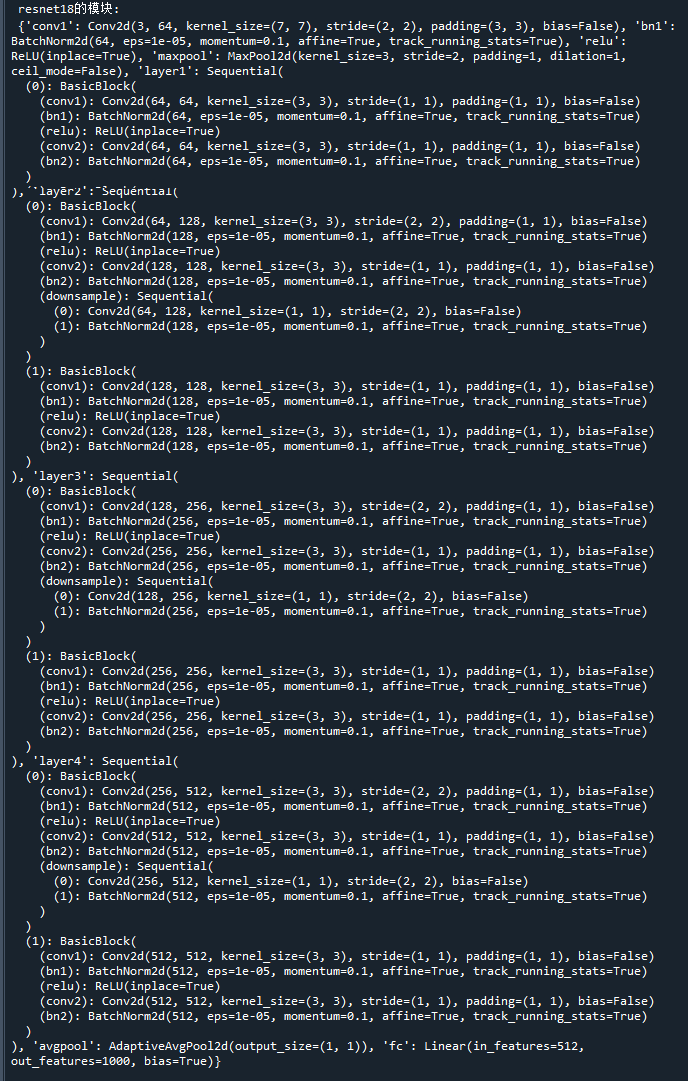
以上就是pytorch中ResNet18的结构了
ResNet神经网络-代码实现
下面展示如何训练一个ResNet18卷积神经网络用于图片类别识别
具体代码如下:
import torchvision
import torch
from torch.utils.data import DataLoader
import numpy as np
model = torchvision.models.resnet18(num_classes=102) # 初始化模型
print('\n resnet18的模块:\n',dict(model.named_children()) )
# 训练函数
def train(dataloader,valLoader,model,epochs,goal,device):
for epoch in range(epochs):
err_num = 0 # 本次epoch评估错误的样本
eval_num = 0 # 本次epoch已评估的样本
print('-----------当前epoch:',str(epoch),'----------------')
for batch, (imgs, labels) in enumerate(dataloader):
# -----训练模型-----
x, y = imgs.to(device), labels.to(device) # 将数据发送到设备
optimizer.zero_grad() # 将优化器里的参数梯度清空
py = model(x) # 计算模型的预测值
loss = lossFun(py, y) # 计算损失函数值
loss.backward() # 更新参数的梯度
optimizer.step() # 更新参数
# ----计算错误率----
idx = torch.argmax(py,axis=1) # 模型的预测类别
eval_num = eval_num + len(idx) # 更新本次epoch已评估的样本
err_num = err_num +sum(y != idx) # 更新本次epoch评估错误的样本
if(batch%10==0): # 每10批打印一次结果
print('err_rate:',err_num/eval_num) # 打印错误率
# -----------验证数据误差---------------------------
model.eval() # 将模型调整为评估状态
val_acc_rate = calAcc(model,valLoader,device) # 计算验证数据集的准确率
model.train() # 将模型调整回训练状态
print("验证数据的准确率:",val_acc_rate) # 打印准确率
if((err_num/eval_num)<=goal): # 检查退出条件
break
print('训练步数',str(epoch),',最终训练误差',str(err_num/eval_num))
# 计算数据集的准确率
def calAcc(model,dataLoader,device):
py = np.empty(0) # 初始化预测结果
y = np.empty(0) # 初始化真实结果
for batch, (imgs, labels) in enumerate(dataLoader): # 逐批预测
cur_py = model(imgs.to(device)) # 计算网络的输出
cur_py = torch.argmax(cur_py,axis=1) # 将最大者作为预测结果
py = np.hstack((py,cur_py.detach().cpu().numpy())) # 记录本批预测的y
y = np.hstack((y,labels)) # 记录本批真实的y
acc_rate = sum(y==py)/len(y) # 计算测试样本的准确率
return acc_rate
# -------模型参数初始化----------------------
def init_param(model):
param_dict = dict(model.named_parameters()) # 获取模型的参数字典
for key in param_dict: # 历遍每个参数,对其初始化
param_name = key.split(".")[-1] # 获取参数的尾缀作为名称
if (param_name=='weight'): # 如果是权重
torch.nn.init.normal_(param_dict[key]) # 则正态分布初始化
elif (param_name=='bias'): # 如果是阈值
torch.nn.init.zeros_(param_dict[key]) # 则初始化为0
#-------------主流程脚本----------------------------------
#-------------------加载数据-----------------------
trainsform =torchvision.transforms.Compose([
torchvision.transforms.Resize([224, 224]),
torchvision.transforms.ToTensor(),
]
)
train_data = torchvision.datasets.Flowers102(
root = 'D:\pytorch\data' # 路径,如果路径有,就直接从路径中加载,如果没有,就联网获取
,split ='train' # 训练数据
,transform = trainsform # 转换数据
,download = True # 是否下载,选为True,就下载到root下面
,target_transform= None)
val_data = torchvision.datasets.Flowers102(
root = 'D:\pytorch\data' # 路径,如果路径有,就直接从路径中加载,如果没有,就联网获取
,split ='test' # 测试数据
,transform = trainsform # 转换数据
,download = True # 是否下载,选为True,就下载到root下面
,target_transform= None)
#-------------------模型训练--------------------------------
trainLoader = DataLoader(train_data, batch_size=30, shuffle=True) # 将数据装载到DataLoader
valLoader = DataLoader(val_data , batch_size=30) # 将验证数据装载到DataLoader
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 设置训练设备
init_param(model) # 初始化模型参数
model = model.to(device) # 发送到设备
lossFun = torch.nn.CrossEntropyLoss() # 定义损失函数为交叉熵损失函数
optimizer = torch.optim.SGD(model.parameters(), lr=0.01,momentum =0.9) # 初始化优化器
train(trainLoader,valLoader,model,1,0.01,device) # 训练模型,训练100步,错误低于1%时停止训练
# -----------模型效果评估---------------------------
model.eval() # 将模型切换到评估状态(屏蔽Dropout)
train_acc_rate = calAcc(model,trainLoader,device) # 计算训练数据集的准确率
print("训练数据的准确率:",train_acc_rate) # 打印准确率
val_acc_rate = calAcc(model,valLoader,device) # 计算验证数据集的准确率
print("验证数据的准确率:",val_acc_rate) 备注:代码未亲测,仅供参考
好了,关于ResNet在CIFAR-10数据集上的相关实验就介绍到这了
End
 评论
评论