本站原创文章,转载请说明来自《老饼讲解-机器学习》www.bbbdata.com
随机森林是一种集成算法,它随机训练多棵弱决策树来进行集体决策,拥有比决策树更好的泛化能力
本文讲解随机森林的原理、模型结构以及随机森林的训练流程,并展示一个随机森林的具体使用例子
通过本文,可以快速了解什么是随机森林模型,如何评估随机森林模型,以及如何使用随机森林进行类别预测
本节讲解随机森林模型的思想与模型表达式,快速了解随机森林是什么
什么是随机森林模型
随机森林(Random Forest)是bagging集成算法的一种实现,它集成多棵Cart决策树来共同决策
由于随机森是通过随机抽取不同样本、不同的变量来训练出多棵弱决策树的,所以称为随机森林
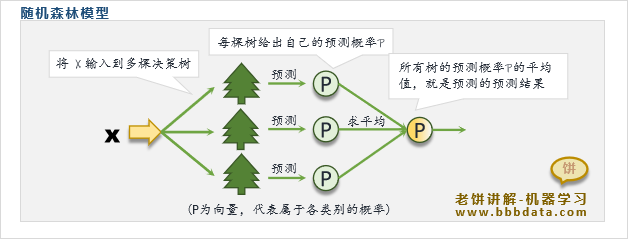
随机森林的模型表达式为:
其中
:随机森林给出的各类别的预测概率
: 第 棵决策树
: 第 棵树对的预测,输出为各个类别的预测概率(行向量)
: 森林规模数
可以看到,随机森林就是将多个Cart决策的预测结果进行平均,作为模型的预测值
本节讲解随机森林是如何训练的,以及随机森林的obb_score是什么
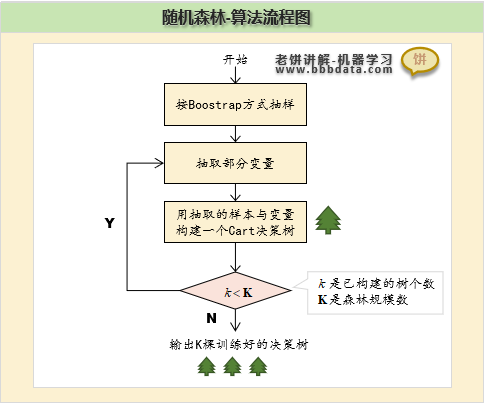
随机森林的具体训练流程
随机森林是如何Bagging的
Bagging注重如何训练出多个有效的弱模型
随机森林以CART决策树作为基模型,它以如下机制训练出多棵弱树:
👉1. 随机样本:使用boostrap抽样来使样本差异化,令每次训练的模型侧重点不一样
boostrap抽样指的是放回式抽样n次(n是整体样本个数)
例如整体样本有n个,然后每次都在整体样本中抽样,抽n次得到n个样本
👉2. 随机变量:每次只随机抽取部分变量来训练Cart决策树,削弱决策树的拟合能力
这样既可以使每棵树使用的变量不一样,同时又能限制树的深度
随机样本和随机变量都能使树模型差异化,同时预防过拟合,使得最终能训练出多棵不同的弱决策树
随机森林的训练流程
随机森林的具体训练流程如下:
1. 样本抽取 : 放回式抽取n(样本个数)次样本
2. 变量抽取:随机抽取m个变量,作为本次决策树的变量
3. 训练弱树 : 用抽取的样本、变量训练Cart决策树
一直训练K棵树为止
简单地说,就是生成k棵树,每棵树用的样本随机抽取,最后k棵树组合在一起就是森林
✍️ 随机森林进行bagging的目的
随机森林简单来说,就是训练多棵弱决策树来共同决策,它的目的是使模型泛化能力更加强
通俗理解随机森林,则是类似多人决策,它未必是最优的,但肯定是中肯的,能避免过激的决策
由于Cart决策树只要深度足够深,就可以拟合出任意形态,所以Cart决策树是极易过拟合的模型
随机森林将决策树进行bagging,主要目的不是为了让模型更加精准,而是怕决策树 "过于精准"
因此随机森林中用的是弱决策树、不易过拟合的决策树,再通过集成决策来提升预测结果准确度
使得最终的随机森林模型,既继承了弱决策树的泛化能力,又有足够的预测精度
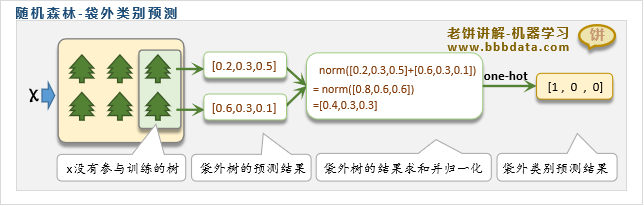
随机森林的模型评估-obb_score
袋外得分obb(out-of-bag)-score是一个用来评估随机森林模型泛化能力的指标
在解释袋外得分之前,不妨先介绍袋外样本和袋外预测的概念
袋外样本:随机森林在训练时使用boostrap进行抽样,所以每个模型实际上只用了部分样本
那些未参与训练的样本就称为该模型的袋外样本
袋外预测:袋外预测是指,每个样本只用该样本不参与训练的模型来对样本进行预测
例如样本A在模型1、3、5中都参与了训练,那么袋外预测就是模型2、4对样本A的预测
在了解袋外样本、袋外预测后,很容易就理解袋外得分了,
袋外得分obb_score就是指所有训练样本进行袋外预测时的准确率
即随机森林可以不需额外预留测试样本,因为它可以使用袋外得分来评估模型的泛化能力
本节展示如何在python中实现随机森林模型来预测样本类别
随机森林-代码实现例子
下面以iris数据为例,展示如何在python中训练一个随机森林模型进行类别预测
随机森林的具体代码示例如下:
"""
本代表用于展示如何使用sklearn实现随机森林模型
代码来自:《老饼讲解-机器学习》 www.bbbdata.com
"""
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
import numpy as np
np.random.seed(888)
#----------加载数据---------------
iris = load_iris() # 加载iris数据
X = iris.data # 样本的X
y = iris.target # 样本的y
#------模型训练与预测---------------
clf = RandomForestClassifier(oob_score=True,max_features=2,n_estimators=100) # 初始化随机森林模型
clf.fit(X, y) # 训练随机森林模型
pred_prob = clf.predict_proba(X) # 预测样本的概率
pred_c = clf.predict(X) # 预测样本的类别
preds = iris.target_names[pred_c]
#-------打印结果 ---------------
print("\n----前5个样本的真实类别:----")
print(iris.target[0:5])
print("\n----前5个样本的预测结果:----")
print(pred_c[0:5])
print("\n----袋外准确率oob_score:----")
print(clf.oob_score_)
print("\n----特征得分:----")
print(clf.feature_importances_)运行结果如下:
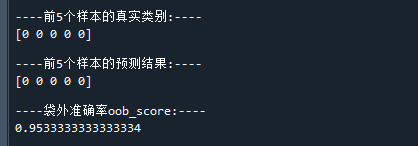
可以看到,模型的预测结果基本是准确的,
进一步地,从模型的袋外预测率为95.3%,可知道模型的泛化能力也不错
✍️ 随机森林训练时重要的超参数
1. 特征最大个数m
特征最大个数m一般远小于总特征个数M,例如
2. 森林规模数K
森林规模数K就是树的棵数,K一般设为100
太小会导致模型准确度不够,太大又会导致模型过于复杂
笔者语
关于如何理解随机森林
随机森林曾经火过一段时间,因为它大大提高了决策树的泛化能力
但由于后来出现了XGboost,现在随机森林也就用得少了
比起随机森林算法本身,它所用的Bagging集成算法的思想贡献更加大
建议读者看完本文后,再看看Bagging算法,再回头理解随机森林就更加深刻了
关于如何自实现随机森林
由于本文主要用于入门快速了解随机森林,所以在本文中,使用了sklearn来实现随机森林
如果不想调用函数,而是自行实现随机森林算法,可参考《课程:随机森林-原理与自实现》
该课程是老饼看完sklearn的源码后,整理而成的课程内容
课程详细讲解如何自实现随机森林,并复现出sklearn的结果,看完就知道sklearn是如何实现随机森林模型的了
好了,以上就是随机森林集成算法的入门原理和使用了~
End
 评论
评论