本站原创文章,转载请说明来自《老饼讲解-机器学习》www.bbbdata.com
本文讲解在逻辑回归做了归一化的情况下,如何提取对应原始数据的模型表达式,
通过该方法,就可以在预测的时候,不用再对数据进行归一化,
同时,也可以看到对应原始数据的权重阈值,方便我们分析问题
本节先介绍为什么要提取、以及如何提取逻辑回归模型原始数据的模型系数
什么是逻辑回归原始数据模型系数
问题背景
在《sklearn提取逻辑回归模型系数》一文中,我们已经讲解如何得到模型的权重和阈值
然而,如果数据在建模之前做了归一化处理,那么从模型中提取到的系数是对应归一化数据的,
在预测时,需要先对X作归一化,再用提取到的公式进行预测,这样显然不够优雅
逻辑回归原始数据模型系数
基于上述问题,我们希望直接提取对应原始数据的模型表达式,
这样在模型使用时,就可以省去归一化的步骤,同时也方便对模型进行一些分析
那如何得到对应原始数据的逻辑回归模型表达式呢?
逻辑回归原始数据系数提取-原理推导
要获取对应原始数据的模型表达式
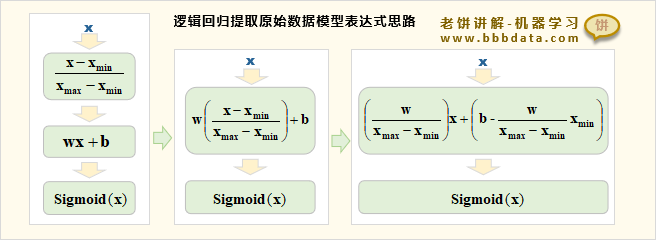
只需要把归一化部分的公式与模型的表达式揉合在一起即可
由于逻辑回归模型内部是线性函数,归一化也是线性函数
因此揉合后并不会改变逻辑回归模型本身,而只是改变了模型系数
公式推导
由于已经知道对应归一化数据的权重 w 和阈值 b,
则模型的预测值为:
(1)式
而由归一化公式,可知归一化数据与原数据x的关系如下:
(2)式
下面揉合模型表达式,从而得到归一化公式
将(2)式代入(1)式即可得:
由上可知:
对应原始数据的权重为:
对应原始数据的阈值为:
注意,上式中,除号和乘法的记法不是非常严谨,除号是对应相除,乘号是矩阵乘法
✍️补充:整体思路梳理
逻辑回归提取原始数据的模型表达式的整体思路如下:
本节展示一个实际例子,讲解如何提取出逻辑回归原始数据的模型表达式
提取逻辑回归原始数据的模型系数-Demo代码
如上节所述,只需要先提取归一化后的w,b
再将它与归一化公式结合,就可以得到原始数据所对应的w,b了
具体代码示例如下:
from sklearn.datasets import load_breast_cancer
from sklearn.linear_model import LogisticRegression
import numpy as np
#----------数据加载-------------------------
data = load_breast_cancer() # 加载数据
X = data.data[:,4:8] # 变量X
y = data.target # 输出y
#---------数据归一化------------------------
xmin = X.min(axis=0) # X的最小值
xmax = X.max(axis=0) # X的最大值
X_norm =(X-xmin)/(xmax-xmin) # 对X进行归一化
#-----逻辑回归模型训练与预测----------------
clf = LogisticRegression(random_state=0) # 初始化逻辑回归模型
clf.fit(X_norm,y) # 训练模型
pred_y = clf.predict(X_norm) # 模型的类别预测
pred_prob_y = clf.predict_proba(X_norm)[:,1] # 模型的概率预测
#------------提取系数w与阈值b---------------
w_norm = clf.coef_[0] # 模型系数(对应归一化数据)
b_norm = clf.intercept_ # 模型阈值(对应归一化数据)
w = w_norm/(xmax-xmin) # 模型系数(对应原始数据)
b = b_norm - (w_norm/(xmax - xmin)).dot(xmin) # 模型阈值(对应原始数据)
self_prob_y = 1/(1+np.exp(-(X.dot(w)+ b) )) # 用公式预测
max_e = abs(pred_prob_y-self_prob_y).max() # 公式预测结果与sklearn预测结果的最大差异
#------------打印信息--------------------------
print("\n------对应归一化数据的模型参数-------") # 打印标题
print( "模型系数(对应归一化数据):",clf.coef_[0]) # 打印模型系数(对应归一化数据)
print( "模型阈值(对应归一化数据):",clf.intercept_) # 打印模型阈值(对应归一化数据)
print("\n------对应原始数据的模型参数-------") # 打印标题
print("模型系数(对应原始数据):",w) # 打印模型系数(对应原始数据)
print("模型阈值(对应原始数据):",b) # 打印模型阈值(对应原始数据)
print("\n提取公式计算的概率与模型概率的最大误差",) # 打印误差代码运行结果如下: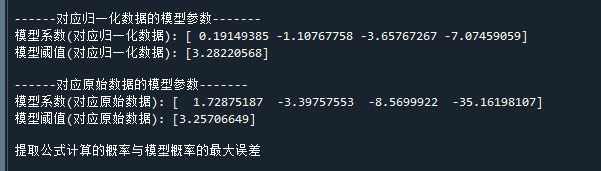
将结果中的模型系数与阈值代回逻辑回归模型,即可得到对应原始数据的模型为:
好了,以上就是如何在sklearn中提取逻辑回归原始数据的模型系数了~
End