本站原创文章,转载请说明来自《老饼讲解-机器学习》www.bbbdata.com
在评分卡中,经常用IV值来判断一个变量是否有价值,或作为入模的筛选条件
本文讲解IV值的计算公式,并展示一个具体的计算例子,以及IV值在评分卡中的常见应用
通过本文,可以了解IV值如何计算,IV值多少才有效,以及如何使用代码计算IV值
本节讲解IV值是什么,并展示IV值的计算公式与计算例子
IV值的计算公式
IV值是什么
IV全称为信息价值(Information Value),它常在评分卡中用于筛选变量
IV的原理是通过评估好、坏样本在变量分布上的差异,从而评估变量对y的信息价值
如图所示,已知好、坏样本在枚举变量上的分布,然后用IV来评估两者的差异
如果IV值较大,则说明该变量有用,对y的预测有价值,反之,如果IV值较小,则说明没有太大价值
IV的计算公式
IV的计算公式如下:
往往也简记为如下形式:
其中,
:坏样本总个数
:坏样本且X为第i组的个数
:好样本且X为第i组的个数
:好样本总个数
备注:IV公式里的 即
本节讲解IV值的具体计算例子,以及在评分卡中的用途
IV值的计算实例
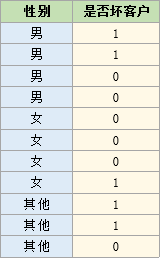
以性别变量为例,性别变量共有三个级别:男、女、其它,如下:
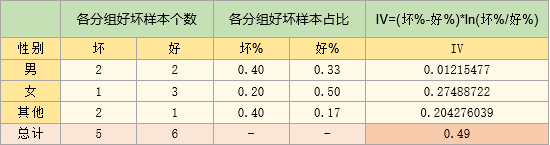
以上述数据为例,通过下表的计算,就可得到性别变量的IV值:
如表,IV的计算共三个步骤:
一、统计各个分组里好坏样本的个数,并算得好坏样本的总数
二、计算各个分组里好、坏样本在"好、坏总样本"的占比
三、根据公式算出每组的IV
四、将每组的IV进行求和,就得到变量的IV值
IV值在评分卡中的应用
IV值在评分卡中的应用场景
在评分卡中,IV值一般有如下的应用
1. 将IV作为变量价值的参考值
即在变量分析时,把IV值计算出来,作为参考
2. 使用IV值来筛掉无效变量
当评分卡的变量很多时,往往会用IV值对变量进行初筛
一般把IV值大于0.1的变量都保留下来,进行下一步分析
在变量很多的时候,这样可以大大减少需要分析的变量
3. 使用IV值来选择入模变量
在自动化建模时,要求无人工参与,此时可以使用IV值来选择入模变量
例如选择IV值大于0.2的变量进行建模,这样可以使建模自动化
IV值多少才有效
IV值越高,变量的价值越高,
一般来说,IV值与变量对好坏客户的区分度的关系如下:
IV < 0.02 :几乎没有区分度,
0.02 <= IV < 0.1 :有微弱的区分度;
0.1 <= IV < 0.3 :有明显的区分度;
0.3 <= IV :较强的区分度
备注:IV值小并不说明变量完全无效,它仅作为参考值,并不是变量有效性的绝对评估
本节展示IV值计算的具体代码实现
IV值计算-代码实现
IV值的计算只需将样本的好、坏占比统计出来,再用公式计算就可以了‘
具体代码实现如下:
"""
本代码用于展示如何计算变量的IV值
本代码来自《老饼讲解-机器学习》www.bbbdata.com
"""
import numpy as np
import pandas as pd
# 函数:用于计算变量的IV
def cal_iv(data):
bad_tt = data['y'].sum() # 坏客户个数
good_tt = data.shape[0] -bad_tt # 好客户个数
df = data.groupby('x')['y'].agg([('bad_cn','sum'),('cn','count')]) # 按组别统计坏客户个数与总客户个数
df['good_cn']=df['cn'] -df['bad_cn'] # 各组的好客户个数
df.loc[df['bad_cn'] ==0,'bad_cn' ] = 1 # 如果坏客户个数为0,则设为1.这样计算iv才不报错
df.loc[df['good_cn']==0,'good_cn'] = 1 # 如果好客户个数为0,则设为1.这样计算iv才不报错
df['bad_rate'] = df['bad_cn']/bad_tt # 坏客户占比
df['good_rate'] = df['good_cn']/good_tt # 好客户占比
df['iv'] =(df['bad_rate']-df['good_rate'])* np.log(df['bad_rate']/df['good_rate']) # 按公式计算IV值
iv = df['iv'].sum() # 计算总的IV值
return iv # 返回IV值
# iv计算的应用示例
data = pd.DataFrame({
'x': ['男','男', '男','男','女','女','女','女','其它','其它','其它'], # 用于计算IV的数据
'y': [1,1,0,0,0,0,0,1,1,1,0]
})
iv = cal_iv(data) # 计算IV值
print('\n数据:\n',data) # 打印变量的数据
print('\niv值:',iv) # 打印变量的IV值
代码运行结果如下:
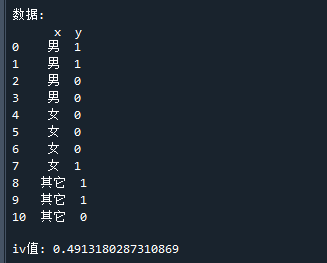
从结果可以看到,IV值为0.49,
它大于0.3,说明变量在好、坏客户的分布上具有较大的区别,即变量对y有很明显的贡献
好了,以上就是评分卡中IV值的计算公式以及计算例子了~
End