本站原创文章,转载请说明来自《老饼讲解-机器学习》www.bbbdata.com
本文展示如何使用python自行实现CART决策树(非调包)和CCP后剪枝算法
算法逻辑来自matlab的fitctree函数,亲测结果与fitctree一致
通过本代码的理解,可以更进一步理解CART决策树的算法逻辑和详细实现细节
本节介绍本文的CART决策树代码实现的内容
CART决策树-代码功能与算法来源
本代码实现CART决策树的构建,预测和CCP剪枝功能。
代码的算法流程来自matlab自带的决策树包,构建的结果与matlab的fitctree一致
最后,代码中附加一个使用Demo,展示代码各个函数功能的使用
CART决策树的相关原理可见:
CART决策树模型简介与实例
CART决策树算法流程
笔者语
由于CART决策树的实现代码非常复杂,并且本文实现的功能较为全面,代码较多
所以笔者并不建议初学者真的去阅读和理解本代码
之所以展示此代码,仅仅是为了告诉大家,如果有必要,是可以具体实现的
另一方面,在学习CART决策树时,如果有细节不理解,也可以借助代码辅助理解
CART决策树代码-运行后执行的内容
代码运行后,就是运行Demo函数,
Demo函数主要是用sklearn自带的iris数据构训练一棵决策树,并进行剪枝,预测等操作
具体实现内容如下:
1、数据生成:使用sklearn自带的iris数据
2、用iris数据构建一棵完全生长的决策树
3、用构建好的决策树对样本进行预测,并打印出预测错误的样本编号
4、将树去掉无效子节点
5、计算各个节点的临界alpha
6、计算并打印CCP路径
7、设定alpha=0.1,进行剪枝
8、根据节点编号进行剪枝
本节展示用python自实现一棵CART决策树的代码
自实现CART决策树的代码
用python自实现CART决策树(分类树)的代码如下:
# -*- coding: utf-8 -*-
"""
决策树CART(分类树)自实现
PASS:算法来源来matlab决策树工具包,笔者亲测,与软件包结果一致。
本代码来自老饼讲解-机器学习:www.bbbdata.com
"""
from sklearn.datasets import load_iris
import numpy as np
from copy import copy
# 节点类:决策树即为一串的树节点连接
class Node(object):
def __init__(self,cMat,sample_idx):
sample_class = cMat[sample_idx].sum(axis=0) # 统计各类别样本个数
class_num = (sample_class>0).sum() # 类别个数
node_class = sample_class.argmax() # 节点类别
sample_num = len(sample_idx) # 样本个数
err_num = sample_num-sample_class[node_class] # 错误样本个数
self.id = None # 节点ID,删除节点时可通过该值删除
self.is_leaf = 0 # 是否是叶子节点
self.left_node = None # 左节点(也是Node类)
self.right_node = None # 右节点(也是Node类)
self.cut_var = None # 分割变量
self.cut_val = None # 分割值
self.sample_idx = sample_idx # 属于该节点的样本索引
self.sample_num = sample_num # 属于该节点的样本个数
self.sample_class = sample_class # 属于该节点的样本属于各类的个数,如[30,10]代表0类30个,1类10个
self.class_num = class_num # 属于该节点的样本类别个数
self.node_class = node_class # 该节点被判为属于哪一类别
self.err_num = err_num # 节点上判断错误的样本个数
self.leaf_errnum = 0 # 该节点下的叶子节点的总错误样本个数,用于计算alpha
self.leaf_nodenum = 0 # 该节点下的叶子节点个数,用于计算alpha
self.alpha = None # 剪枝系数alpha
# 将节点改为叶子节点
def be_leaf(self):
self.left_node = None # 将左节点置空
self.right_node = None # 将右节点置空
self.cut_var = None # 将切割变量置空
self.cut_val = None # 将切割阈值置空
self.is_leaf = 1 # 标记为叶子节点
# 将节点深拷贝(采用递归拷贝)
def copy(self):
if(self.is_leaf==0): # 如果不是叶子节点
left_node = self.left_node.copy() # 拷贝左节点
right_node = self.right_node.copy() # 拷贝右节点
new_node = copy(self) # 拷贝自身
new_node.sample_idx = self.sample_idx.copy() # 拷贝节点样本索引
new_node.sample_class = self.sample_class.copy() # 拷贝节点样本类别
new_node.left_node = left_node # 设置左节点
new_node.right_node = right_node # 设置右节点
if(self.is_leaf==1): # 如果是叶子节点
new_node=copy(self) # 拷贝自身
new_node.sample_idx = self.sample_idx.copy() # 拷贝节点样本索引
new_node.sample_class = self.sample_class.copy() # 拷贝节点样本类别
return new_node
# 计算使用变量x,切值为cut_val时的收益函数(gini)
def cal_gain(x,cMat,cut_val):
is_left = x<=cut_val # 样本是否是左节点
left_rate = is_left.sum()/len(is_left) # 左节点样本个数占比
right_rate = 1- left_rate # 右节点样本个数占比
left_cMat = cMat[is_left] # 左节点类别
right_cMat = cMat[~is_left] # 右节点类别
p_left = left_cMat.sum(axis=0)/left_cMat.sum() # 左节点各类别占比
if (right_cMat.sum()>0): # 如果右节点有样本
p_right = right_cMat.sum(axis=0)/right_cMat.sum() # 计算右节点的类别占比
else: # 否则
p_right = right_cMat.sum(axis=0) # 右节点的类别占比全为0
g_left = 1- (p_left**2).sum() # 左节点基尼系数
g_right = 1- (p_right**2).sum() # 右节点基尼系数
gain = -(left_rate)*g_left - (right_rate)*g_right # 收益值:-左右基尼系数加权和
return gain # 返回收益值
# 找出x变量的最佳切割点
def find_best_cut(x,cMat):
unique_x = np.unique(x) # 先对x去重
best_cut_val = (unique_x[0]+unique_x[1])/2 if len(unique_x)>1 else unique_x[0] # 初始化最佳切割点
best_g = cal_gain(x,cMat,best_cut_val) # 初始化最佳收益
for i in range(1,len(unique_x)-1): # 逐个切割点循环
cut_val = (unique_x[i]+unique_x[i+1])/2 # 当前切割点
g = cal_gain(x,cMat,cut_val) # 当前切割点的收益
if g>best_g: # 如果当前收益大于最佳收益
best_cut_val = cut_val # 将当前切割点作为最佳切割点
best_g = g # 将当前收益作为最佳收益
return best_g,best_cut_val # 返回最佳收益和最佳切割点
# 将类别标签转为one-hot矩阵
def class2Cmat(y):
c_name = np.unique(y) # 将y去重
c_num = len(c_name) # 类别个数
cMat = np.zeros([len(y),c_num]) # 初始化one-hot矩阵
for i in range(c_num): # 逐个类别循环
cMat[y==c_name[i],i]=1 # 设置当前类别的样本的one-hot
return cMat,c_name # 返回one-hot矩阵与类别名称
# 删除无用叶子: 叶子不能降低判别误差,则删
def prune_bad(node):
un_use_node = [node] # 将根节点入栈
delete_bad = 0 # 初始化是否删除过节点
while(len(un_use_node)>0): # 如果栈里还有节点
cur_node = un_use_node.pop() # 弹出栈里的节点
if(cur_node.is_leaf==1): # 如果是叶子节点
pass # 不必判断
elif((cur_node.left_node.is_leaf==1) &(cur_node.right_node.is_leaf==1)): # 如果左右都是叶子,则判断是否删除
if((cur_node.left_node.err_num+ cur_node.right_node.err_num) >=cur_node.err_num): # 叶子节点不能降低判别误差,则删
cur_node.be_leaf() # 将节点置为叶子节点
delete_bad = 1 # 标记:已删过节点
else: # 如果不是叶子,也不是倒算第二层节点
un_use_node.append(cur_node.left_node) # 把左叶子入栈
un_use_node.append(cur_node.right_node) # 把右叶子入栈
if(delete_bad==1): # 如果删过节点
prune_bad(node) # 则将树重新裁剪
# 给节点及其子孙设置id序号
def set_node_id(node,next_id):
node.id = next_id # 设置当前节点的ID
if(node.is_leaf==0): # 如果节点不是叶子
next_id = set_node_id(node.left_node,next_id+1) # 给左节点设置ID
set_node_id(node.right_node,next_id) # 给右节点设置ID
return next_id+1 # 返回最新节点编号
# 计算各个节点的临界alpha,并返回最小临界alpha
def cal_alpha(node,total_num=None):
total_num = node.sample_num if(total_num is None) else total_num # 初始化总样本数
# 如果不是叶子节点,获取左右节点下的叶子节点的错误样本个数,并计算临界alpha
if(node.is_leaf==0): # 如果不是叶子节点,
left_err,left_nodenum,left_min_alpha = cal_alpha(node.left_node,total_num) # 获取左节点下的叶子节点的错误样本个数
right_err,right_nodenum,right_min_alpha = cal_alpha(node.right_node,total_num) # 获取右节点下的叶子节点的错误样本个数
node.leaf_errnum = left_err + right_err # 计算当前节点下的叶子节点的错误样本个数
node.leaf_nodenum = left_nodenum + right_nodenum # 计算当前了点下的叶子节点个数
node.alpha = max(((node.err_num-node.leaf_errnum)/total_num)/(node.leaf_nodenum-1),0) # 计算临界alpha
min_alpha = min(left_min_alpha,right_min_alpha,node.alpha) # 记录最小临界alpha
# 如果是叶子节点,直接获取叶子节点错误个数
else: # 如果是叶子节点
node.leaf_errnum = node.err_num # 当前节点错误样本个数就是叶子节点错误样本个数
node.leaf_nodenum = 1 # 叶子节点个数
min_alpha = float('inf') # 设置最小临界alpha为无穷大
return node.leaf_errnum,node.leaf_nodenum,min_alpha # 返回错误样本数、叶子数、最小临界alpha
# 对临界alpha<=alpha的节点剪枝
def prune_alpha(node,alpha):
prune_list =[] # 初始化剪枝节点列表
if(node.is_leaf==1): # 如果当前节点是叶子
return prune_list # 无需处理,直接返回剪枝列表
if(node.alpha<=alpha): # 如果节点alpha小于剪枝alpha
prune_list.append(node.id) # 将当前节点添加到剪枝列表
left_prune_list = prune_alpha(node.left_node,0) # 对左节点继续用alpha=0进行剪枝
right_prune_list = prune_alpha(node.right_node,0) # 对右节点继续用alpha=0进行剪枝
node.be_leaf() # 将节点设为叶子节点
else: # 如果节点alpha不小于剪枝alpha
left_prune_list = prune_alpha(node.left_node,alpha) # 对左节点继续用alpha进行剪枝
right_prune_list = prune_alpha(node.right_node,alpha) # 对右节点继续用alpha进行剪枝
prune_list.extend(left_prune_list) # 添加左节点的剪枝节点
prune_list.extend(right_prune_list) # 添加右节点的剪枝节点
return prune_list # 返回剪枝节点列表
# 获取迭代剪枝的最小alpha
'''
先计算树最小临界alpha,剪掉最小临界alpha的叶子,再计算树小临界,再剪..再计算,再剪,直到只剩根节点,
返回每轮的最小临界alpha
'''
def cal_prune_list(node):
cnode = node.copy()
min_alpha_list = []
prune_list = []
while((cnode.is_leaf==0) and len(min_alpha_list)<1000):
leaf_errnum,leaf_nodenum,min_alpha = cal_alpha(cnode)
cur_prune_list = prune_alpha(cnode,min_alpha)
prune_list.append(cur_prune_list)
min_alpha_list.append(min_alpha)
return min_alpha_list,prune_list
#根据alpha值最大剪枝
def prune(node,alpha):
p_node = node.copy()
min_alpha_list,prune_list = cal_prune_list(p_node)
prune_term = np.argwhere(np.array(min_alpha_list)<=alpha)
if(len(prune_term)>0):
prune_term=prune_term[-1][0]+1
for i in range(prune_term):
leaf_errnum,leaf_nodenum,min_alpha = cal_alpha(p_node)
prune_alpha(p_node,min_alpha)
return p_node
# 剪掉指定ID的节点
def prune_nodes(node,id_list):
p_node = node.copy() # 入参的节点作为父节点
un_use_node=[p_node] # 将父节点入栈
while((len(un_use_node)>0) and len(id_list)>0 ): # 如果还有待剪节点(同时要求栈里有节点)
cur_node = un_use_node.pop() # 从栈中弹出一个节点
if(cur_node.id in id_list): # 如果当前节点在待剪列表中
cur_node.be_leaf() # 将当前节点置为叶子
elif(cur_node.is_leaf==0): # 如果当前节点不是叶子
un_use_node.append(cur_node.left_node) # 将左叶子节点入栈
un_use_node.append(cur_node.right_node) # 将右叶子节点入栈
return p_node
# predict,预测函数
def predict(node,x):
while(node.is_leaf==0): # 如果节点不是叶子
node = node.left_node if x[node.cut_var]<=node.cut_val else node.right_node # 根据切割变量与切割阈值,判断节点走向左还是右
return node.node_class # 返回最终节点的类别
# 打印树
def print_node(node,deep=0,var_name_list=[],show_sample_class=0,show_alpha_info=0):
node_id = '('+str(node.id)+')'
alpha_info = ''
if (show_alpha_info==1):
alpha_info = ' (leaf_errnum:'+str(node.leaf_errnum)+')' + ' (alpha:'+str(node.alpha)+')'
if(node.is_leaf==0):
var_name = 'x' + str(node.cut_var) if(len(var_name_list)==0) else var_name_list[node.cut_var]
left_sample_class = "("+str(node.left_node.sample_class)+")" if show_sample_class==1 else ''
right_sample_class = "("+str(node.right_node.sample_class)+")" if show_sample_class==1 else ''
print(' |'*deep+"--"+node_id+var_name+"<="+str(node.cut_val)+left_sample_class+alpha_info)
print_node(node.left_node,deep+1
,var_name_list=var_name_list
,show_sample_class=show_sample_class
,show_alpha_info=show_alpha_info)
print(' |'*deep+"--"+node_id+var_name+">"+str(node.cut_val)+right_sample_class+alpha_info)
print_node(node.right_node
,deep+1
,var_name_list=var_name_list
,show_sample_class=show_sample_class
,show_alpha_info=show_alpha_info)
else:
print(' |'*deep+"--"+node_id+"class="+str(node.node_class) +alpha_info)
# 主程序:构建树
def build_tree(x,y):
min_leaf_num = 10 # 参数预设
n_samples = x.shape[0] # 样本个数
n_feture = x.shape[1] # 特征个数
cMat,c_name = class2Cmat(y) # 将y转为one-hot矩阵
root_node = Node(cMat,np.arange(n_samples)) # 树初始化
un_use_node = [root_node] # 将根节点入栈
# 树构建主流程
while(len(un_use_node)>0 ): # 如果还有节点未分裂完成
# --------- 弹出节点 ----------------
cur_node = un_use_node.pop() # 弹出一个未完成分裂的节点
node_x = x[cur_node.sample_idx] # 获取节点样本的x
cur_cMat = cMat[cur_node.sample_idx] # 获取节点样本的y(类别矩阵形式)
not_leaf = (cur_node.sample_num>=min_leaf_num)& (cur_node.class_num>1) # 判断是否未达叶子条件
# ---------- 分裂或设为叶子 --------
if(not_leaf): # 如果未能成为叶子,继续分裂
best_var = 0 # 预设第一个变量为最佳变量
best_g,best_cut_val = find_best_cut(node_x[:,best_var],cur_cMat) # 预设第一个变量的最佳切割为节点最佳切割
# 历遍变量,找出每个变量的最佳切割,再比较哪个变量的最佳切割最好
for i in range(1,n_feture): # 历遍变量
g,cut_val = find_best_cut(node_x[:,i],cur_cMat) # 找出该变量的最佳切割,与最佳收益
if g>best_g: # 更新最佳变量、最佳切割、最佳收益
best_g = g # 更新最佳收益
best_cut_val = cut_val # 更新最佳切割
best_var = i # 更新最佳变量
cur_node.cut_var = best_var # 把最佳变量作为本节点最佳变量
cur_node.cut_val = best_cut_val # 把最佳切割作为本节点最佳切割
is_left = node_x[:,best_var]<=best_cut_val # 找出左节点样本
cur_node.left_node = Node(cMat,cur_node.sample_idx[is_left ]) # 新建左节点
cur_node.right_node = Node(cMat,cur_node.sample_idx[~is_left ]) # 新建右节点
un_use_node.extend([cur_node.left_node,cur_node.right_node]) # 把左右节点添加到分裂池
else:
cur_node.be_leaf() # 如果节点已达叶子条件,则设为叶子节点
set_node_id(root_node,1) # 给树每个节点添加序号
return root_node # 返回根节点,即树
# 各个功能的使用demo
def test_demo():
# -----加载数据-----------------
iris = load_iris() # 加载iris数据
var_name_list =['sepal_length','sepal_width','petal_length','petal_width'] # 变量名称
x = iris.data # 变量x
y = iris.target # 标签y
# ----构建完全生长的树-----------
tree = build_tree(x,y) # 构建一棵完全生长的决策树
# -----预测---------------------
predict_y = np.zeros(y.shape) # 初始化预测结果
for i in range(x.shape[0]): # 逐个样本预测
predict_y[i] = predict(tree,x[i]) # 当前样本的预测值
# -----打印信息-------------------------------------
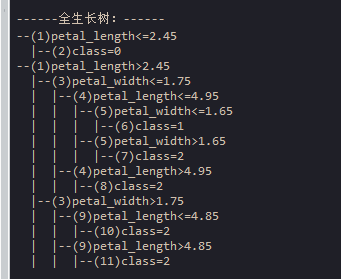
print("\n------全生长树:------") # 打印
print_node(tree,var_name_list=var_name_list) # 打印树结构
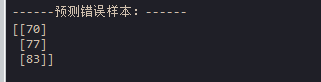
print("\n------预测错误样本:------") # 打印
print(np.argwhere(predict_y != y )) # 打印预测错误的样本序号
#-----剪枝-----------------------------------
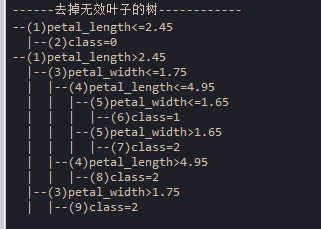
# 去掉无效叶子
prune_bad(tree) # 去掉无效叶子
print("\n------去掉无效叶子的树------------") # 打印树
print_node(tree,var_name_list=var_name_list) # 打印树结构
# 根据alpha剪枝
# 带临界alpha信息的树
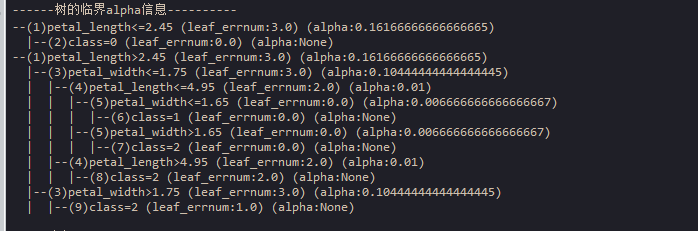
cal_alpha(tree,tree.sample_num) # 获取临界alpha信息
print("\n------树的临界alpha信息----------") # 打印
print_node(tree,var_name_list=var_name_list,show_alpha_info=1) # 打印树结构
# 多轮迭代式剪枝得到的CCP路径
min_alpha_list,prune_list = cal_prune_list(tree) # 模拟迭代式删除临界alpha
print("\n--CCP路径--") # 打印
print("每轮alpha:",min_alpha_list) # 打印临界alpha
print("每轮剪除节点:",prune_list) # 打印对应剪除的节点
p_tree = prune(tree,0.1 ) # 根据alpha剪枝(会多轮迭代)
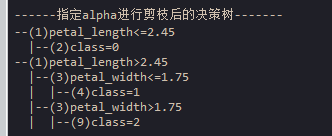
print("\n------指定alpha进行剪枝后的决策树-------") # 打印
print_node(p_tree,var_name_list=var_name_list) # 打印树
# 其它剪枝
p_tree = prune_nodes(p_tree,[5,9]) # 指定节点剪枝
prune_alpha(tree,0.1) # 根据alpha剪枝(只剪一轮)
# 调用测试Demo
test_demo()代码运行结果
代码运行后的输出如下:
1、用iris作为训练数据构建的完全生长的决策树
2、决策树在训练样本中预测错误的样本编号
3、将完全生长的树去掉无效节点的后得到的决策树
4、展示树的节点信息,包括alpha
5、打印出ccp路径

6、根据CCP路径信息,我们指定alpha=0.1,进行剪枝后得到的决策树
本节对代码中的相关函数进行说明
test_demo: 测试用例主函数,直接运行时就是执行该函数。
1、数据生成:使用sklearn自带的iris数据
2、用iris数据构建一棵完全生长的决策树
3、用构建好的决策树对样本进行预测,并打印出预测错误的样本编号
4、将树去掉无效子节点
5、计算各个节点的临界alpha
6、计算并打印CCP路径
7、设定alpha=0.1,进行剪枝
8、根据节点编号进行剪枝
build_tree:决策树构建主函数,用于构建一棵CART决策树
决策树构建主函数,用于构建一棵CART决策树
print_node:打印决策树
将决策树结构打印出来,并可选择是否显示节点上的相关信息。
predict:决策树的预测函数
传入决策树和要预测的x,即可得到决策树的预测结果
cal_prune_list:计算CCP路径
每次按最小alpha值,迭代剪枝,直到剪完整棵树,最后返回剪枝的路径。
注:剪枝动作是模拟进行的,并不影响树本身。
prune_bad:对无效节点进行剪枝
如果节点的分枝并不能降低判别误差,说明节点的分枝是无益的,对这些无效节点进行剪枝
prune_nodes:决策树的节点剪枝函数
传入要剪掉的节点编号,对树进行剪枝
prune:决策树的alpha剪枝函数
传入alpha值,按alpha值进行剪枝
8个辅助函数:用于辅助计算的函数。
Node:节点类
cal_alpha:计算各个节点的临界alpha,并返回最小临界alpha
prune_alpha:剪掉当前树节点alpha<=某个值的节点
set_node_id:重新设置子孙节点编号
find_best_cut:找出x变量的最佳切割点
cal_gain:找出x变量计算使用变量x,切值为cut_val时的收益函数(gini)最佳切割点
class2Cmat:将类别转为类别矩阵
cal_gain:找出x变量计算使用变量x,切值为cut_val时的收益函数(gini)最佳切割点
以上就是自现实一棵CART决策树的代码了~
End