本站原创文章,转载请说明来自《老饼讲解-机器学习》www.bbbdata.com
CART决策树包括了分类树与回归树,其中回归树用于解决回归拟合问题
CART回归树与分类树极为相似,仅是在CART分类树上做一些修改
本文介绍CART回归树,通过本文,了解CART回归树是如何利用决策树解决回归问题的
本节基于CART分类树的基础上,讲解CART回归树是什么
CART回归树-模型结构
在了解CART分类树的基础上,CART回归树的学习非常容易
回归树与分类树的不同,在于回归树的输出变量y是连续数值变量
因此,在CART分类树的基础上,稍作修改就是CART回归树
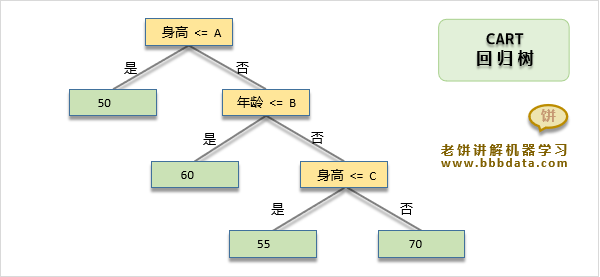
如下是一棵CART回归树,它通过身高、年龄来预测体重:
CART回归树与CART分类树一样,仍然是一棵二叉树,只是最终叶子节点是一个数值
也就是说,CART回归树最后虽然输出的是数值,但它的输出是可枚举的
CART回归树的构建
CART回归树整体构建算法类似于CART分类树
关键有以下两点修改:
1.输出类型的修改
叶子节点输出的不是类别,而是节点上所有y的均值
2.分割评估函数的修改
回归树构建过程中,节点分割评估不用基尼指数,而是平方差
如下:
备注:本文参考自 李航《统计学习方法》
End
 评论
评论