本站原创文章,转载请说明来自《老饼讲解-机器学习》www.bbbdata.com
二分类模型是机器学习中最常见的模型,用于评估二分类模型的指标特别多
本文介绍二分类模型的四种基本样本以及常用的指标TPR、TNR、FPR、FNR、F1-Score等等
通过本文,可以清晰了解二类分模型有哪些指标,以及各种指标的计算公式和使用领域
本节介绍二分类模型中的四个基本样本类型,它是计算各种指标的基础
二分类中的基本样本类型
在二分类模型中,根据样本的真实类别与预测类别,分为四种类型:TP、TN、FN、FP:

TP (True Positive) 真阳:被判定为正样本,事实上也是正样本(被认为是1,实际也是1)
TN (True Negative) 真阴:被判定为负样本,事实上也是负样本(被认为是0,实际也是0)
FP (False Positive) 假阳:被判定为正样本,事实上却是负样本(被认为是1,实际却是0)
FN (False Negative) 假阴:被判定为负样本,事实上却是正样本(被认为是0,实际却是1)
✍️如何理解正样本
正样本并不是指好的样本,正样本指的是我们的目标样本
例如在医学中,我们的目标是找出病人,那么病人是正样本,而不是健康的人
例如产品质检中,我们希望找出不合格的产品,那么不合格的产品就是正样本
二分类模型的常用指标不是很多,但同一个指标在不同领域往往有不同名称
本节按不同的使用领域,介绍二分类模型中的各种常用指标与名称
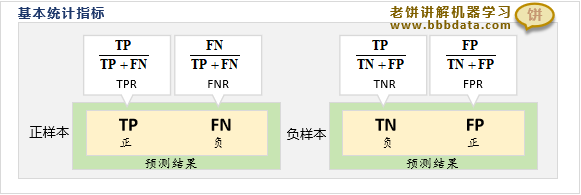
第一套:基本统计常用指标
TPR、FNR、TNR、FPR是4个最基本的常用基础指标,它们的意义分别如下:
1. TPR(True PositiveRate)
TPR是正样本的预测正确率:预测正确的正样本个数/正样本总个数
2. FNR(False NegativeRate)
FNR是正样本的预测错误率:正样本预测为负样本的个数/正样本总个数
3. TNR(True NegativeRate)
TNR是负样本的预测正确率:预测正确的负样本个数/负样本总个数
4. FPR(False PositiveRate)
FPR是负样本的预测错误率:负样本预测为正样本的个数/负样本总个数
第二套:机器学习指标
1. 准确率(Accuracy):
准确率是总样本预测正确的占比:预测正确的样本个数/总样本个数
2. 错误率(Error rate)
错误率是总样本预测错误的占比:预测错误的样本个数/总样本个数
3. 召回率(Recall)
召回率是正样本的预测正确率:预测正确的正样本个数/正样本总个数
4. 精确率(Precision)
精确率是预测为正的样本的准确率:预测为正且真实为正的样本个数/预测为正的样本个数
5. F值(F-Measure或F-Score)
6. F1值(F1-Score)
F1-Score是F-Score取时的值,如下:
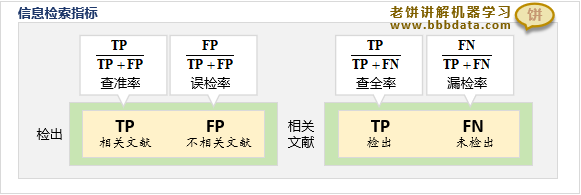
第三套:信息检索指标
在信息检索上常用的指标为查准率、误检率、查全率与漏检率,如下:
1. 查准率
查准率是预测为正的样本的准确率:预测为正且真实为正的样本个数/预测为正的样本个数
2. 误检率
误检率是预测为正的样本的错误率:预测为正但实为负的样本个数/预测为正的样本个数
3. 查全率
查全率是正样本的预测正确率:预测正确的正样本个数/正样本总个数
4. 漏检率
漏检率是正样本的预测错误率:正样本预测为负样本的个数/正样本总个数
第四套:故障检测指标
1. 检出率(DR,Detection Rate)
检出率是预测为正的样本在总样本中的占比:预测为正的样本个数/总样本个数
2. 漏警率(MAR,Missing Alarm Rate)
漏警率是正样本的预测错误率:正样本预测为负样本的个数/正样本总个数
3. 虚警率(FAR,False Alarm Rate)
虚警率是负样本的预测错误率:负样本预测为正样本的个数/负样本总个数
第五套:生信指标
下面是生信、医学上常用的相关指标:
1. 真阳性率(TPR):参见TPR
2. 假阴性率(FNR):参见FNR
3. 真阴性率(TNR):参见TNR
4. 假阳性率( FPR):参见FPR
5. 灵敏度(Sensitive)
灵敏度是正样本的预测正确率:预测正确的正样本个数/正样本总个数
6. 特效度(Specificity)
特效度是负样本的预测正确率:预测正确的负样本个数/负样本总个数
End
 评论
评论