
本站原创文章,转载请说明来自《老饼讲解-深度学习》www.bbbdata.com
RNN-Encoder-Decoder模型往往都加入了上下文来解决编码信息消失的问题
本文讲解带上下文的RNN-Encoder-Decoder模型结构和它的具体计算流程,以及为什么要加入上下文
通过本文,可以快速了解什么是上下文的RNN-Encoder-Decoder模型,以及在Encoder-Decoder模型中加入上下文的意义
本节讲解带上下文的RNN-Encoder-Decoder模型的结构
带上下文的RNN-Encoder-Decoder模型
带上下文的RNN-Encoder-Decoder模型是对基础RNN-Encoder-Decoder模型的一种改进
它出自GRU的论文:《Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation》
该论文除了贡献了GRU神经网络之外,还在RNN-Encoder-Decoder中加入了上下文,使得上下文成为Encoder-Decoder的一种常用技术
它的结构如下:
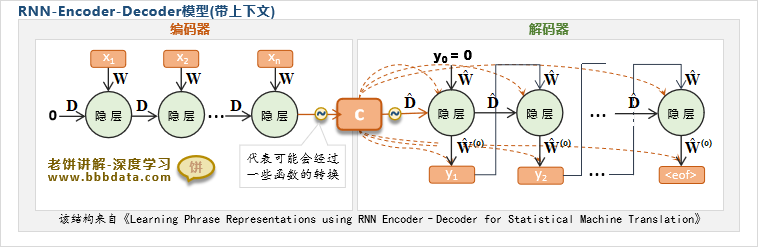
Encoder-解说
Encoder部分是一个没有输出的RNN,将输入序列投到该RNN中,然后得到最后时刻得到的隐层
特别地,可以将最后的隐层作为编码信息c,即
也可以把最后一个隐层使用一些函数转换后再作为编码信息c,即
编码器的意义就是不断用输入更新隐层,这样最后时刻的隐层就承载了所有输入的信息
Decoder-解说
Decoder部分是一个带有输出的RNN,下面细看它的实时输入与延迟输入值:
1. 关于实时输入: 解码器用上一时刻的输出作为当前时刻的实时输入,即
解码器实时输入的初始值用0来初始化:
即实时输入为:
2. 关于延迟输入:它的延迟输入用c来初始化
即延迟输入为:
3. 关于隐层与输出层的外部输入:
敲黑板!编码信息c除了用于初始化解码器的隐节点外,还作为隐层与输出层的上下文外部输入!
也就是说,隐层除了实时输入和延迟输入,还增加了上下文输入c!如下:
同样,输出除了以隐层作为输入,也使用了实时输入和与上下文输入c,如下:
✍️与<基础RNN-Encoder-Decoder模型>的差异
与《RNN-Encoder-Decoder基础模型》模型的差异主要有如下三点
1. 编码信息c的差异:编码信息c不一定直接使用编码器最后的隐层
而是将经由一个函数转换后再作为可作为编码信息
2. 解码器的初始值:解码器的实时输入用0来初始化
3. 解码器引入上下文:编码信息c除了用于初始化解码器的隐节点外,还作为隐层与输出层的上下文输入
为什么需要引入上下文
带上下文的RNN-Encoder-Decoder引入上下文c作为解码器的外部输入,那么为什么需要引入上下文c作为外部输入呢?
主要是因为解码器经过几轮迭代后,隐节点中所存留的c的信息将会非常弱,以致于解码器经过一些时刻后,难以利用编码信息c
但事实上,解码器任何时刻的输出都是与编码器输入紧密相关的,也即与编码c紧密相关
例如将"今天吃饼干"翻译成英文时,解码器任何时刻的输出都是需要参考原始中文输入"今天吃饼干"的
所以在解码器中将c作为每个时刻的上下文输入,这样相当于让每个时刻的输出都能参考原始输入信息
本节讲解带上下文的RNN-Encoder-Decoder模型的具体计算流程
带上下文的RNN-Encoder-Decoder模型-计算流程
不妨假设样本的每个输出序列都以'<eof>'作为结束符
带上下文的RNN-Encoder-Decoder的具体计算流程如下:
一、迭代编码器
编码器的迭代公式如下:
其中,初始条件
二、计算编码信息c
编码信息的计算方式有两种:
(1) 用编码器最后一时刻的隐层作为编码信息c
(2) 将作一些转换后再得到c
例如:
和是模型要训练的参数
三、计算解码器的输出
1. 初始化
初始化0时刻的隐节点:
初始化初始时刻的输入:
2. 按以下公式计算解码器,直到输出为终止符'<eof>'则终止
编后语
✍️关于本文对论文原文结构的差异
本文中所介绍的"带上下文的RNN-Encoder-Decoder模型"主要参考自《Learning Phrase...Translation》
但为了模型的通用性以及学习的便利性,作了一些必要的简化
1. 论文中使用的是GRU模型,本文使用经典RNN进行替代
2. 论文在解码器输出层添加了maxout层,本文略去
3. 论文中解决的是翻译问题,所以在输入输出层都涉及了NLP的嵌入矩阵转换,本文略去
✍️关于版本的先后
本文讲解的模型来自提出GRU的论文《Learning Phrase... Translation》
虽然看起来该模型是改进《Sequence to Sequence ...Networks》所使用的基础RNN-Encoder-Decoder模型
但实际上《Learning...Translation》比《Sequence ...Networks》发表得要更早,后者的参考文献里就有前者
所以,本文所介绍的《Learning...Translation》应该视为对历史RNN-Encoder-Decoder的改进,而不是对《Sequence ...Networks》中的结构的改进
End