本站原创文章,转载请说明来自《老饼讲解-机器学习》www.bbbdata.com
超参数网格搜索一般与K-Fold结合使用,是机器学习中一种常用于参数调优的方法
本文讲解超参数网格搜索是什么,以及K-Fold的流程,并展示超参数网格搜索与K-Fold的使用示例
通过本文,可以快速了解超参数网格搜索与K-Fold是什么,如何使用它们来对模型进行超参数调优
本节讲解什么是参数网格搜索,什么是K-Fold交叉验证,以及K-Fold交叉验证的流程
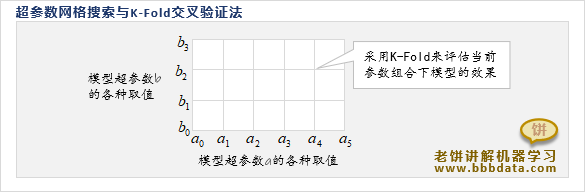
超参数网格搜索与K-Fold是什么
超参数网格搜索(Param Grid Serch)是机器学习中对模型超参数进行调优的常用一种方法
简单来说,网格搜索就是每个超参数都设置几个要尝试的值,然后历遍所有超参数的组合
最后,对比各组超参数的建模效果,哪组超参数的建模结果最好,就用哪组超参数来建模
由于模型的训练往往有一定的随机性,直接使用模型效果来评估超参数效果往往不够稳定
所以,超参数网格搜索一般使用K-Fold交叉验证法来评估模型超参数的效果,它更为平稳
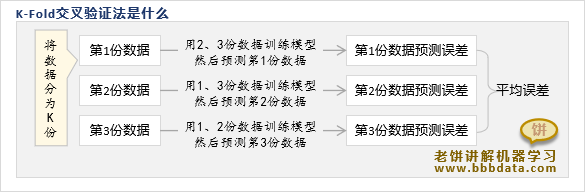
K-Fold交叉验证
K-Fold又称为K折交叉验证法,K-Fold交叉验证方法如下:
每个模型以其中一份数据作为测试数据,其余作为训练数据,再计算该份数据的预测结果
最后综合K个模型就得到K份测试数据(即整体数据)的预测结果,进而评估模型的预测效果
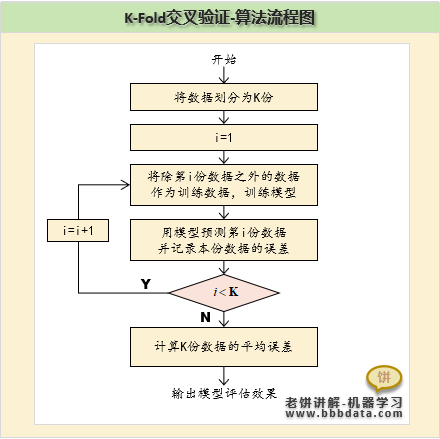
K-Fold的算法流程
对于要评估的超参数,K-Fold按如下方法评估超参数的建模效果
1. 将数据划分为K份
K根据数据量来具体设置,一般设为5或10
2. 循环:i=1,2,3...K
(1)将第i份数据作为测试集,其余数据作为训练集训练模型
(2)记录当前模型的测试误差
3. 计算K份数据的平均测试误差
本节展示如何在网格扫描超参数时,使用K-Fold交叉验证法来评估模型效果
调用sklearn来实现K-Fold参数搜索
在sklearn中可以调用GridSearchCV进行参数网格搜索,它同时提供了K-Fold功能
下面我们用K-Fold与参数网格搜索优化决策树模型的超参数criterion、max_depth
具体代码示例如下:
from sklearn.datasets import load_iris
from sklearn.model_selection import GridSearchCV
from sklearn import metrics
from sklearn import tree
import pandas as pd
#----------------数据准备----------------------------
iris = load_iris() # 加载数据
X = iris.data # 用iris.data作为X
y = iris.target # 用iris.target作为y
# --------使用网格搜索进行超参数调优------------------
clf = tree.DecisionTreeClassifier() # 初始化模型
param_grid = {'criterion': ['gini','entropy'],'max_depth': [3,4,5,None]} # 设置要扫描的参数
def err(y_true, y_pred): # 定义误差的计算方法
return (y_true==y_pred).mean()
# 初始化网格扫描
grid_search = GridSearchCV(clf # 模型
,param_grid # 参数网格
,cv = 5 # cv=5代表用5折交叉验证法
,scoring = metrics.make_scorer(err)) # 这里指定了模型的评估函数
grid_search.fit(X, y) # 进行网格扫描
rs = pd.DataFrame(grid_search.cv_results_['params']) # 提取扫描的参数
rs['score'] =grid_search.cv_results_['mean_test_score'] # 拼接参数的评估结果
print(rs) # 打印结果运行结果如下:
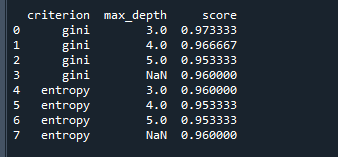
结果中展示了criterion、max_depth不同取值时,决策树模型的评估结果
根据上表,我们可以选择出合适的criterion、max_depth作为最终建模时所使用的超参数
自实现K-Fold法交叉验证
下面展示如何不调用sklearn的函数包,自行实现网格搜索与K-Fold交叉验证
我们仍然以优化决策树模型参数criterion、max_depth为例,实现K-Fold与网格搜索的应用
具体代码如下:
from sklearn.datasets import load_iris
from sklearn import tree
import pandas as pd
import numpy as np
#----------------数据准备----------------------------
iris = load_iris() # 加载数据
X = iris.data # 用iris.data作为X
y = iris.target # 用iris.target作为y
k = 5 # 数据分割的份数k
#--------------将数据分割为k份----------------------
rand_idx = np.random.choice(len(y), size=len(y), replace=False) # 打乱数据索引
data_len = int(len(y)/k) # 每份数据的大小
start_idx = [i*data_len for i in range(k)] # 每份数据的起始位置
end_idx = [(i+1)*data_len for i in range(k)] # 每份数据的结束位置
end_idx[-1] = len(y) # 修正最后一份数据的结束位置
#---------------超参数网络搜索----------------------
criterion_list = ['gini','entropy'] # 超参数criterion要扫描的值
max_depth_list = [3,4,5,None] # 超参数max_depth要扫描的值
result = pd.DataFrame(columns=['criterion','max_depth','acc']) # 初始化结果表
for criterion in criterion_list: # 历遍超参数criterion
for max_depth in max_depth_list: # 历遍超参数max_depth
y_pred = np.array([]) # 初始化预测结果
for i in range(k): # 逐份数据作为预测数据
train_idx = np.concatenate((rand_idx[0:start_idx[i]],rand_idx[end_idx[i]:])) # 本次训练数据的索引
test_idx = rand_idx[start_idx[i]:end_idx[i]] # 本次测试数据的索引
clf = tree.DecisionTreeClassifier(criterion=criterion,max_depth=max_depth) # 用当前超参数初始化树模型
clf = clf.fit(X[train_idx,:], y[train_idx]) # 用训练数据训练决策树
y_pred = np.concatenate((y_pred,clf.predict(X[test_idx,:]))) # 预测测试数据的类别
acc = (y_pred==y[rand_idx]).mean() # 计算准确率
result_dict = {'criterion':criterion,'max_depth':max_depth,'acc':acc} # 本次的模型效果
result = result.append(result_dict, ignore_index=True) # 记录本次模型效果
print(result) # 打印最终的结果
运行结果如下:
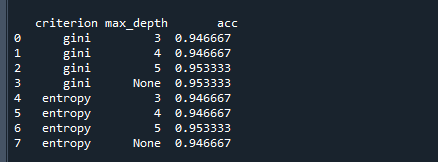
结果中展示了criterion、max_depth不同取值时,模型的准确率acc
根据上表,我们可以选择出合适的criterion、max_depth作为最终建模时所使用的超参数
End