本站原创文章,转载请说明来自《老饼讲解-机器学习》www.bbbdata.com
交叉熵(Cross Entropy)是信息论中一个重要的概念,它可用来评估认知概率与真实概率的差异
本文讲解交叉熵的定义、计算公式,以及交叉熵在机器学习中的用途,并分析交叉熵与信息熵的区别
通过本文可以快速了解交叉熵是什么,交叉熵如何计算,以及交叉熵的意义和具体用途
本节介绍信息学中的交叉熵,包括交叉熵的概念和交叉熵的公式
交叉熵的定义与计算公式
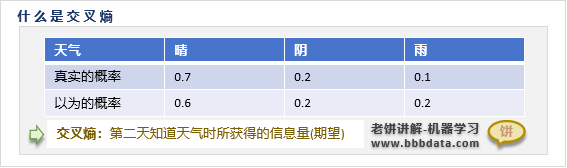
什么是交叉熵
设有种取值,我们认为第 种取值的概率为,事实上第种取值的概率为
则交叉熵的定义为:在知道X的真实取值时,我们所获得的信息量期望
即交叉熵是在不知道真实分布、仅有猜测的概率时,我们知道真相时所获得的信息量期望
交叉熵的计算公式
根据上述交叉熵的定义,交叉熵就是信息量期望,即可得到
交叉熵的计算公式:
,
其中,为x取值为时,所获得的信息量
特别地,当h取为香农信息量时,则称为香农交叉熵,如下
香农交叉熵的计算公式:
其中,:我们认为取值为 的概率
:取值为 的真正概率
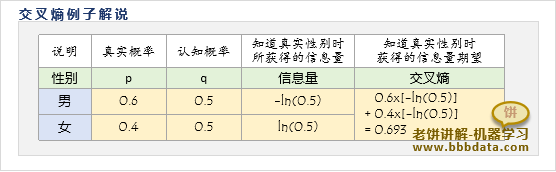
交叉熵计算-举例说明
假设已知一个人的性别为男、女的概率分别为,而我们认为是
那么对任意一个人,在知道他是男/女的时候,分别获得信息量
因此,在知道性别时获得的信息量期望(即交叉熵)为
这种在我们认为概率是q,而事实是p时,"知道x真实值"时获得的信息量期望就称为x的交叉熵
本节介绍交叉熵的用途与意义,并辨析交叉熵与信息熵的差异,进一步掌握交叉熵
交叉熵的意义和用途
交叉熵的意义
交叉熵的意义是,它可用于评估我们认知概率的准确性
在认知概率与真实概率一致,即P(x)=Q(x)时,交叉熵是最小的(可参考KL散度中的证明)
而随着我们的认知概率与真实概率出现的偏差越来越大,交叉熵也越来越大
因此,交叉熵往往用于评估我们对事件的认知概率的准确程度,交叉熵越小则说明越准确
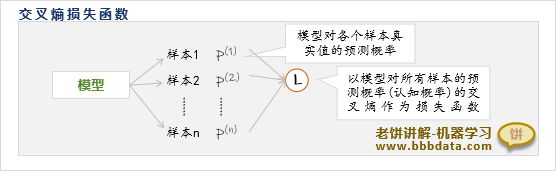
交叉熵的用途-交叉熵损失函数
交叉熵在机器学习最常见的是用来评估概率模型的准确性,此时称为交叉熵损失函数
交叉熵损失函数就是用交叉熵来评估模型给出每个训练样本属于真实标签的概率的准确性
交叉熵损失函数越小,则模型给的概率越准,此时模型能尽量大地减少真实 值的信息量
交叉熵与信息熵的区别
交叉熵与信息熵在定义上比较相似,往往对两者的区别并不是那么清晰
下面我们具体地辨析与指出两者的区别,以免混淆它们的使用场景
交叉熵与信息熵的辨析
不妨先回顾一下交叉熵与信息熵的定义:
1. 信息熵 :信息熵指的是在客观概率p下,知道真相时所获得的信息量的期望
2. 交叉熵 :交叉熵指的是在认知概率q下,知道真相时所获得的信息量的期望
交叉熵与信息熵看起来很相似,但它们其实很不同,主要是它们的评估对象不同
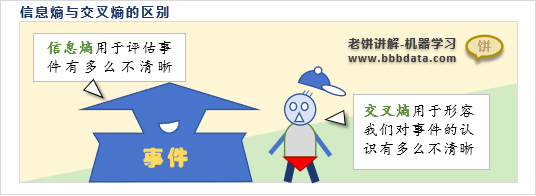
信息熵的评估对象主要是事件本身,它用于评估事件本身的混沌程度,不清晰度
交叉熵的评估对象则是"我们",它用于评估我们对"事件的概率"认知的准确程度
通俗来说,信息熵在描述事件,而交叉熵的焦点在于描述我们
信息熵是描述一件事所带来的震惊程度,而交叉熵则描述这个事件会怎么震惊我们
信息熵是注定的、不可变的,而交叉熵则是可变的,它随着我们认知的提高而降低
好了,交叉熵就介绍到这里了,相信已经知道交叉熵是什么了吧~
End